Transfer logins and passwords to destination server (Server A) using scripts generated on source server (Server B)
On server A, start SQL Server Management Studio, and then connect to the instance of SQL Server from which you moved the database.
Open a new Query Editor window, and then run the following script.
USE master GO IF OBJECT_ID (‘sp_hexadecimal’) IS NOT NULL DROP PROCEDURE sp_hexadecimal GO CREATE PROCEDURE sp_hexadecimal @binvalue varbinary(256), @hexvalue varchar (514) OUTPUT AS DECLARE @charvalue varchar (514) DECLARE @i int DECLARE @length int DECLARE @hexstring char(16) SELECT @charvalue = ‘0x’ SELECT @i = 1 SELECT @length = DATALENGTH (@binvalue) SELECT @hexstring = ‘0123456789ABCDEF’ WHILE (@i <= @length) BEGIN DECLARE @tempint int DECLARE @firstint int DECLARE @secondint int SELECT @tempint = CONVERT(int, SUBSTRING(@binvalue,@i,1)) SELECT @firstint = FLOOR(@tempint/16) SELECT @secondint = @tempint – (@firstint*16) SELECT @charvalue = @charvalue + SUBSTRING(@hexstring, @firstint+1, 1) + SUBSTRING(@hexstring, @secondint+1, 1) SELECT @i = @i + 1 END
SELECT @hexvalue = @charvalue GO
IF OBJECT_ID (‘sp_help_revlogin’) IS NOT NULL DROP PROCEDURE sp_help_revlogin GO CREATE PROCEDURE sp_help_revlogin @login_name sysname = NULL AS DECLARE @name sysname DECLARE @type varchar (1) DECLARE @hasaccess int DECLARE @denylogin int DECLARE @is_disabled int DECLARE @PWD_varbinary varbinary (256) DECLARE @PWD_string varchar (514) DECLARE @SID_varbinary varbinary (85) DECLARE @SID_string varchar (514) DECLARE @tmpstr varchar (1024) DECLARE @is_policy_checked varchar (3) DECLARE @is_expiration_checked varchar (3)
DECLARE @defaultdb sysname
IF (@login_name IS NULL) DECLARE login_curs CURSOR FOR
SELECT p.sid, p.name, p.type, p.is_disabled, p.default_database_name, l.hasaccess, l.denylogin FROM sys.server_principals p LEFT JOIN sys.syslogins l ON ( l.name = p.name ) WHERE p.type IN ( ‘S’, ‘G’, ‘U’ ) AND p.name <> ‘sa’ ELSE DECLARE login_curs CURSOR FOR
SELECT p.sid, p.name, p.type, p.is_disabled, p.default_database_name, l.hasaccess, l.denylogin FROM sys.server_principals p LEFT JOIN sys.syslogins l ON ( l.name = p.name ) WHERE p.type IN ( ‘S’, ‘G’, ‘U’ ) AND p.name = @login_name OPEN login_curs
FETCH NEXT FROM login_curs INTO @SID_varbinary, @name, @type, @is_disabled, @defaultdb, @hasaccess, @denylogin IF (@@fetch_status = -1) BEGIN PRINT ‘No login(s) found.’ CLOSE login_curs DEALLOCATE login_curs RETURN -1 END SET @tmpstr = ‘/* sp_help_revlogin script ‘ PRINT @tmpstr SET @tmpstr = ‘** Generated ‘ + CONVERT (varchar, GETDATE()) + ‘ on ‘ + @@SERVERNAME + ‘ */’ PRINT @tmpstr PRINT ” WHILE (@@fetch_status <> -1) BEGIN IF (@@fetch_status <> -2) BEGIN PRINT ” SET @tmpstr = ‘– Login: ‘ + @name PRINT @tmpstr IF (@type IN ( ‘G’, ‘U’)) BEGIN — NT authenticated account/group
SET @tmpstr = ‘CREATE LOGIN ‘ + QUOTENAME( @name ) + ‘ FROM WINDOWS WITH DEFAULT_DATABASE = [‘ + @defaultdb + ‘]’ END ELSE BEGIN — SQL Server authentication — obtain password and sid SET @PWD_varbinary = CAST( LOGINPROPERTY( @name, ‘PasswordHash’ ) AS varbinary (256) ) EXEC sp_hexadecimal @PWD_varbinary, @PWD_string OUT EXEC sp_hexadecimal @SID_varbinary,@SID_string OUT
— obtain password policy state SELECT @is_policy_checked = CASE is_policy_checked WHEN 1 THEN ‘ON’ WHEN 0 THEN ‘OFF’ ELSE NULL END FROM sys.sql_logins WHERE name = @name SELECT @is_expiration_checked = CASE is_expiration_checked WHEN 1 THEN ‘ON’ WHEN 0 THEN ‘OFF’ ELSE NULL END FROM sys.sql_logins WHERE name = @name
IF ( @is_policy_checked IS NOT NULL ) BEGIN SET @tmpstr = @tmpstr + ‘, CHECK_POLICY = ‘ + @is_policy_checked END IF ( @is_expiration_checked IS NOT NULL ) BEGIN SET @tmpstr = @tmpstr + ‘, CHECK_EXPIRATION = ‘ + @is_expiration_checked END END IF (@denylogin = 1) BEGIN — login is denied access SET @tmpstr = @tmpstr + ‘; DENY CONNECT SQL TO ‘ + QUOTENAME( @name ) END ELSE IF (@hasaccess = 0) BEGIN — login exists but does not have access SET @tmpstr = @tmpstr + ‘; REVOKE CONNECT SQL TO ‘ + QUOTENAME( @name ) END IF (@is_disabled = 1) BEGIN — login is disabled SET @tmpstr = @tmpstr + ‘; ALTER LOGIN ‘ + QUOTENAME( @name ) + ‘ DISABLE’ END PRINT @tmpstr END
FETCH NEXT FROM login_curs INTO @SID_varbinary, @name, @type, @is_disabled, @defaultdb, @hasaccess, @denylogin END CLOSE login_curs DEALLOCATE login_curs RETURN 0 GO
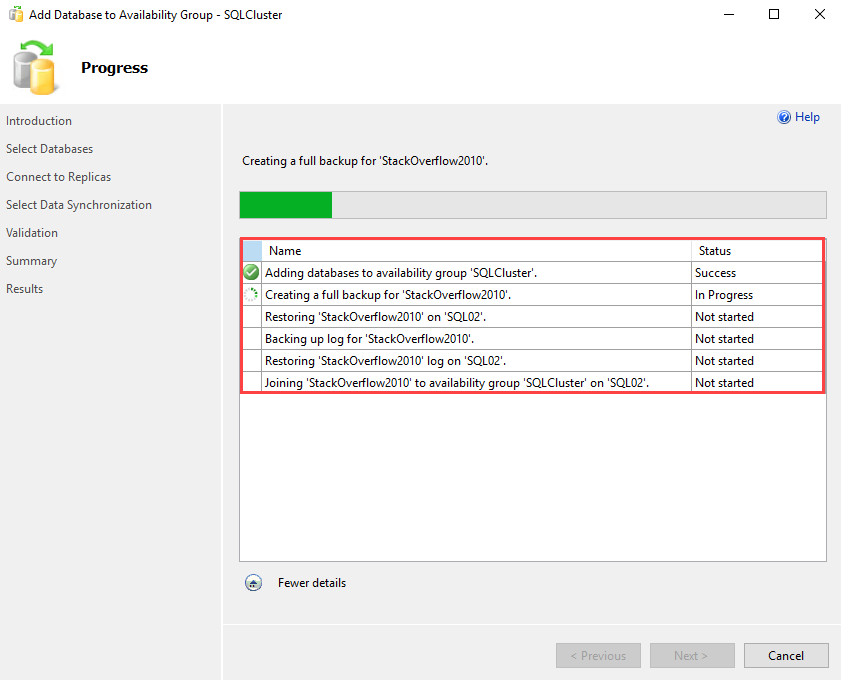
Note This script creates two stored procedures in the master database. The procedures are named sp_hexadecimal and sp_help_revlogin.
Run the following statement in the same or a new query window:
EXEC sp_help_revlogin
The output script that the sp_help_revlogin stored procedure generates is the login script. This login script creates the logins that have the original Security Identifier (SID) and the original password.
Steps on the destination server (Server B):
On server B, start SQL Server Management Studio, and then connect to the instance of SQL Server to which you moved the database.
Important Before you go to step 2, review the information in the “Remarks” section below.
Open a new Query Editor window, and then run the output script that’s generated in step 2 of the preceding procedure.
— Revoke all permissions on table C0012433944 to everyone except sysadmins
use [CreditDataWarehouse] go
DENY delete ON OBJECT::dbo.C0012433944 TO cdw_Asm_User; GO DENY insert ON OBJECT::dbo.C0012433944 TO cdw_Asm_User; GO DENY references ON OBJECT::dbo.C0012433944 TO cdw_Asm_User; GO DENY select ON OBJECT::dbo.C0012433944 TO cdw_Asm_User; GO DENY update ON OBJECT::dbo.C0012433944 TO cdw_Asm_User; GO
DENY delete ON OBJECT::dbo.C0012433944 TO CDW_Dev; GO DENY insert ON OBJECT::dbo.C0012433944 TO CDW_Dev; GO DENY references ON OBJECT::dbo.C0012433944 TO CDW_Dev; GO DENY select ON OBJECT::dbo.C0012433944 TO CDW_Dev; GO DENY update ON OBJECT::dbo.C0012433944 TO CDW_Dev; GO
DENY delete ON OBJECT::dbo.C0012433944 TO CDW_Web; GO DENY insert ON OBJECT::dbo.C0012433944 TO CDW_Web; GO DENY references ON OBJECT::dbo.C0012433944 TO CDW_Web; GO DENY select ON OBJECT::dbo.C0012433944 TO CDW_Web; GO DENY update ON OBJECT::dbo.C0012433944 TO CDW_Web; GO
DENY delete ON OBJECT::dbo.C0012433944 TO CMPROD; GO DENY insert ON OBJECT::dbo.C0012433944 TO CMPROD; GO DENY references ON OBJECT::dbo.C0012433944 TO CMPROD; GO DENY select ON OBJECT::dbo.C0012433944 TO CMPROD; GO DENY update ON OBJECT::dbo.C0012433944 TO CMPROD; GO
DENY delete ON OBJECT::dbo.C0012433944 TO [DBG\cdw_dataloader-g]; GO DENY insert ON OBJECT::dbo.C0012433944 TO [DBG\cdw_dataloader-g]; GO DENY references ON OBJECT::dbo.C0012433944 TO [DBG\cdw_dataloader-g]; GO DENY select ON OBJECT::dbo.C0012433944 TO [DBG\cdw_dataloader-g]; GO DENY update ON OBJECT::dbo.C0012433944 TO [DBG\cdw_dataloader-g]; GO
DENY delete ON OBJECT::dbo.C0012433944 TO [DBG\philma]; GO DENY insert ON OBJECT::dbo.C0012433944 TO [DBG\philma]; GO DENY references ON OBJECT::dbo.C0012433944 TO [DBG\philma]; GO DENY select ON OBJECT::dbo.C0012433944 TO [DBG\philma]; GO DENY update ON OBJECT::dbo.C0012433944 TO [DBG\philma]; GO
DENY delete ON OBJECT::dbo.C0012433944 TO [dbg\svc_CDW_SSAS]; GO DENY insert ON OBJECT::dbo.C0012433944 TO [dbg\svc_CDW_SSAS]; GO DENY references ON OBJECT::dbo.C0012433944 TO [dbg\svc_CDW_SSAS]; GO DENY select ON OBJECT::dbo.C0012433944 TO [dbg\svc_CDW_SSAS]; GO DENY update ON OBJECT::dbo.C0012433944 TO [dbg\svc_CDW_SSAS]; GO
— Create Switcher job on both SQL Instances USE [msdb] GO
/ Object: Job [CreditDataWarehouse DB Encryption switcher] Script Date: 06/05/2019 10:11:32 / BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 / Object: JobCategory [[Uncategorized (Local)]] Script Date: 06/05/2019 10:11:32 / IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]’ AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N’JOB’, @type=N’LOCAL’, @name=N'[Uncategorized (Local)]’ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
END
DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N’CreditDataWarehouse DB Encryption switcher’, @enabled=0, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N’A job to monitor the CreditDataWarehouse database for failover and if one is spotted to update the master key to re-enable decryption.’, @category_name=N'[Uncategorized (Local)]’, @owner_login_name=N’sa’, @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback / Object: Step [Check for failover and if so refresh master key] Script Date: 06/05/2019 10:11:32 / EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N’Check for failover and if so refresh master key’, @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N’TSQL’, @command=N’IF EXISTS(select * from sys.databases where name=”CreditDataWarehouse” and state_desc=”ONLINE”) BEGIN IF EXISTS(SELECT * FROM CreditDataWarehouse.dbo.C0012433944 WHERE [servername] != @@SERVERNAME) BEGIN DECLARE @PASSWORD VARCHAR(128) SELECT @PASSWORD = secret FROM CreditDataWarehouse.dbo.C0012433944 DECLARE @SQL VARCHAR(1000) = ”use CreditDataWarehouse; OPEN MASTER KEY DECRYPTION BY PASSWORD = ””” + @PASSWORD + ”””; ALTER MASTER KEY DROP ENCRYPTION BY SERVICE MASTER KEY ; ALTER MASTER KEY ADD ENCRYPTION BY SERVICE MASTER KEY;CLOSE MASTER KEY; ” DECLARE @SQL2 VARCHAR(1000) = ”update CreditDataWarehouse.dbo.C0012433944 set [servername] = @@servername;” EXEC(@SQL) EXEC(@SQL2) PRINT ”OPEN MASTER KEY DECRYPTION” END END GO’, @database_name=N’master’, @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N’Every 10 seconds’, @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=2, @freq_subday_interval=10, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20190430, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N’c384ab01-0fa6-400c-a797-e80fbabf7c20′ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)’ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave:
use msdb go DECLARE @dbname sysname SET @dbname = NULL –set this to be whatever dbname you want SELECT bup.server_name AS [Server], bup.database_name AS [Database], CONVERT(DECIMAL(9,2),bup.compressed_backup_size/1024/1024/1024.0) compressed_backup_sizeInGB, CONVERT(DECIMAL(9,2),backup_size/1024/1024/1024.0) backup_sizeInGB, bup.backup_start_date AS [Backup Started], bup.backup_finish_date AS [Backup Finished] ,CAST((CAST(DATEDIFF(s, bup.backup_start_date, bup.backup_finish_date) AS int))/3600 AS varchar) + ‘ hours, ‘
CAST(((CAST(DATEDIFF(ss, bup.backup_start_date, bup.backup_finish_date) AS int))/60)%60 AS varchar)+ ‘ minutes, ‘
CAST((CAST(DATEDIFF(s, bup.backup_start_date, bup.backup_finish_date) AS int))%60 AS varchar)+ ‘ seconds’ AS [Total Time], case when bup.backup_finish_date is null then ‘Not Completed’ Else ‘Çompleted’ END Status FROM msdb.dbo.backupset bup WHERE bup.backup_set_id IN (SELECT MAX(backup_set_id) FROM msdb.dbo.backupset WHERE database_name = ISNULL(@dbname, database_name) –if no dbname, then return all AND type = ‘D’ –only interested in the time of last full backup GROUP BY database_name) /* COMMENT THE NEXT LINE IF YOU WANT ALL BACKUP HISTORY */ AND bup.database_name IN (SELECT name FROM master.dbo.sysdatabases) ORDER BY bup.database_name
go
SELECT js.step_name as TSMPush, case run_status when 1 then ‘Completed’ else ‘Failed’ end as Status, –h.step_id, h.job_id, run_date, run_time, retries_attempted, [message],
FROM msdb.dbo.[sysjobhistory] h INNER JOIN msdb.dbo.sysjobs AS j on j.job_id = h.job_id iNNER JOIN msdb.dbo.sysjobsteps AS js on j.job_id = js.job_id and h.step_id =js.step_id where j.name = ‘DBAG Backup Database – zzzTOTALzzz’ and h.step_id =2 order by run_date
go
Declare @daysToAverage smallint = 30;
Declare @avgRunTime Table ( job_id uniqueidentifier , avgRunTime int );
/* We need to parse the schedule into something we can understand */ Declare @weekDay Table ( mask int , maskValue varchar(32) );
Insert Into @weekDay Select 1, ‘Sunday’ Union All Select 2, ‘Monday’ Union All Select 4, ‘Tuesday’ Union All Select 8, ‘Wednesday’ Union All Select 16, ‘Thursday’ Union All Select 32, ‘Friday’ Union All Select 64, ‘Saturday’;
/* First, let’s get our run-time average */ Insert Into @avgRunTime Select job_id , Avg((run_duration/10000) * 3600 + (run_duration/100%100)60 + run_duration%100) As ‘avgRunTime’ / convert HHMMSS to seconds */ From msdb.dbo.sysjobhistory Where step_id = 0 — only grab our total run-time And run_status = 1 — only grab successful executions And msdb.dbo.agent_datetime(run_date, run_time) >= DateAdd(day, -@daysToAverage, GetDate()) Group By job_id;
/* Now let’s get our schedule information */ With myCTE As( Select sched.name As ‘scheduleName’ , sched.schedule_id , jobsched.job_id , sched.enabled , Case When sched.freq_type = 1 Then ‘Once’ When sched.freq_type = 4 And sched.freq_interval = 1 Then ‘Daily’ When sched.freq_type = 4 Then ‘Every ‘ + Cast(sched.freq_interval As varchar(5)) + ‘ days’ When sched.freq_type = 8 Then Replace( Replace( Replace(( Select maskValue From @weekDay As x Where sched.freq_interval & x.mask <> 0 Order By mask For XML Raw) , ‘”/>’, ”) + Case When sched.freq_recurrence_factor <> 0 And sched.freq_recurrence_factor = 1 Then ‘; weekly’ When sched.freq_recurrence_factor <> 0 Then ‘; every ‘ + Cast(sched.freq_recurrence_factor As varchar(10)) + ‘ weeks’ End When sched.freq_type = 16 Then ‘On day ‘ + Cast(sched.freq_interval As varchar(10)) + ‘ of every ‘ + Cast(sched.freq_recurrence_factor As varchar(10)) + ‘ months’ When sched.freq_type = 32 Then Case When sched.freq_relative_interval = 1 Then ‘First’ When sched.freq_relative_interval = 2 Then ‘Second’ When sched.freq_relative_interval = 4 Then ‘Third’ When sched.freq_relative_interval = 8 Then ‘Fourth’ When sched.freq_relative_interval = 16 Then ‘Last’ End + Case When sched.freq_interval = 1 Then ‘ Sunday’ When sched.freq_interval = 2 Then ‘ Monday’ When sched.freq_interval = 3 Then ‘ Tuesday’ When sched.freq_interval = 4 Then ‘ Wednesday’ When sched.freq_interval = 5 Then ‘ Thursday’ When sched.freq_interval = 6 Then ‘ Friday’ When sched.freq_interval = 7 Then ‘ Saturday’ When sched.freq_interval = 8 Then ‘ Day’ When sched.freq_interval = 9 Then ‘ Weekday’ When sched.freq_interval = 10 Then ‘ Weekend’ End + Case When sched.freq_recurrence_factor <> 0 And sched.freq_recurrence_factor = 1 Then ‘; monthly’ When sched.freq_recurrence_factor <> 0 Then ‘; every ‘ + Cast(sched.freq_recurrence_factor As varchar(10)) + ‘ months’ End When sched.freq_type = 64 Then ‘StartUp’ When sched.freq_type = 128 Then ‘Idle’ End As ‘frequency’ , IsNull(‘Every ‘ + Cast(sched.freq_subday_interval As varchar(10)) + Case When sched.freq_subday_type = 2 Then ‘ seconds’ When sched.freq_subday_type = 4 Then ‘ minutes’ When sched.freq_subday_type = 8 Then ‘ hours’ End, ‘Once’) As ‘subFrequency’ , Replicate(‘0’, 6 – Len(sched.active_start_time)) + Cast(sched.active_start_time As varchar(6)) As ‘startTime’ , Replicate(‘0’, 6 – Len(sched.active_end_time)) + Cast(sched.active_end_time As varchar(6)) As ‘endTime’ , Replicate(‘0’, 6 – Len(jobsched.next_run_time)) + Cast(jobsched.next_run_time As varchar(6)) As ‘nextRunTime’ , Cast(jobsched.next_run_date As char(8)) As ‘nextRunDate’ From msdb.dbo.sysschedules As sched Join msdb.dbo.sysjobschedules As jobsched On sched.schedule_id = jobsched.schedule_id Where sched.enabled = 1 )
/* Finally, let’s look at our actual jobs and tie it all together / Select job.name As ‘jobName’ , sched.scheduleName , sched.frequency , sched.subFrequency ,SUSER_SNAME(job.owner_sid) as Owner , CASE job.enabled WHEN 1 THEN ‘Yes’ else ‘No’ END as Enabled , CASE sched.enabled WHEN 1 THEN ‘Yes’ else ‘No’ END as Scheduled , c.name AS Category , SubString(sched.startTime, 1, 2) + ‘:’ + SubString(sched.startTime, 3, 2) + ‘ – ‘ + SubString(sched.endTime, 1, 2) + ‘:’ + SubString(sched.endTime, 3, 2) As ‘scheduleTime’ — HH:MM , SubString(sched.nextRunDate, 1, 4) + ‘/’ + SubString(sched.nextRunDate, 5, 2) + ‘/’ + SubString(sched.nextRunDate, 7, 2) + ‘ ‘ + SubString(sched.nextRunTime, 1, 2) + ‘:’ + SubString(sched.nextRunTime, 3, 2) As ‘nextRunDate’ / Note: the sysjobschedules table refreshes every 20 min, so nextRunDate may be out of date */ , art.avgRunTime As ‘avgRunTime_inSec’ — in seconds , (art.avgRunTime / 60) As ‘avgRunTime_inMin’ — convert to minutes
From msdb.dbo.sysjobs As job JOIN msdb.dbo.syscategories c (NOLOCK) ON job.category_id = c.category_id Join myCTE As sched On job.job_id = sched.job_id Left Join @avgRunTime As art On job.job_id = art.job_id Where job.enabled = 1 — do not display disabled jobs Order By nextRunDate; go
SET NOCOUNT ON DECLARE @MaxLength INT SET @MaxLength = 50
DECLARE @xp_results TABLE ( job_id uniqueidentifier NOT NULL, last_run_date nvarchar (20) NOT NULL, last_run_time nvarchar (20) NOT NULL, next_run_date nvarchar (20) NOT NULL, next_run_time nvarchar (20) NOT NULL, next_run_schedule_id INT NOT NULL, requested_to_run INT NOT NULL, request_source INT NOT NULL, request_source_id sysname COLLATE database_default NULL, running INT NOT NULL, current_step INT NOT NULL, current_retry_attempt INT NOT NULL, job_state INT NOT NULL )
DECLARE @job_owner sysname
DECLARE @is_sysadmin INT SET @is_sysadmin = isnull (is_srvrolemember (‘sysadmin’), 0) SET @job_owner = suser_sname ()
INSERT INTO @xp_results EXECUTE sys.xp_sqlagent_enum_jobs @is_sysadmin, @job_owner
UPDATE @xp_results SET last_run_time = right (‘000000’ + last_run_time, 6), next_run_time = right (‘000000’ + next_run_time, 6)
SELECT j.name AS JobName, j.enabled AS Enabled, sl.name AS OwnerName, CASE x.running WHEN 1 THEN ‘Running’ ELSE CASE h.run_status WHEN 2 THEN ‘Inactive’ WHEN 4 THEN ‘Inactive’ ELSE ‘Completed’ END END AS CurrentStatus, coalesce (x.current_step, 0) AS CurrentStepNbr, CASE WHEN x.last_run_date > 0 THEN convert (datetime, substring (x.last_run_date, 1, 4) + ‘-‘ + substring (x.last_run_date, 5, 2) + ‘-‘ + substring (x.last_run_date, 7, 2) + ‘ ‘ + substring (x.last_run_time, 1, 2) + ‘:’ + substring (x.last_run_time, 3, 2) + ‘:’ + substring (x.last_run_time, 5, 2) + ‘.000’, 121 ) ELSE NULL END AS LastRunTime, CASE h.run_status WHEN 0 THEN ‘Fail’ WHEN 1 THEN ‘Success’ WHEN 2 THEN ‘Retry’ WHEN 3 THEN ‘Cancel’ WHEN 4 THEN ‘In progress’ END AS LastRunOutcome, durationHHMMSS = STUFF(STUFF(REPLACE(STR(h.run_duration,7,0), ‘ ‘,’0′),4,0,’:’),7,0,’:’)
FROM @xp_results x LEFT JOIN msdb.dbo.sysjobs j ON x.job_id = j.job_id LEFT OUTER JOIN msdb.dbo.syscategories c ON j.category_id = c.category_id LEFT OUTER JOIN msdb.dbo.sysjobhistory h ON x.job_id = h.job_id AND x.last_run_date = h.run_date AND x.last_run_time = h.run_time AND h.step_id = 0 LEFT OUTER JOIN sys.syslogins sl ON j.owner_sid = sl.sid order by LastRunTime,Jobname asc
The Enterprise Policy Management Framework (EPM) is a solution to extend SQL Server Policy-Based Management to all versions of SQL Server in an enterprise, including SQL Server 2000 and SQL Server 2005. The EPM Framework will report the state of specified SQL Server instances against policies that define intent, desired configuration, and deployment standards.
When the Enterprise Policy Management Framework (EPM) is implemented, policies will be evaluated against specified instances of SQL Server through PowerShell. This solution will require at least one instance of SQL Server 2008. The PowerShell script will run from this instance through a SQL Server Agent job or manually through the PowerShell interface. The PowerShell script will capture the policy evaluation output and insert the output to a SQL Server table. SQL Server Reporting Services (2008 or above) reports will deliver information from the centralized table.
This solution requires the following components to be configured in your environment. All SQL Server requirements listed below may be executed from and managed on the same instance:
SQL Server (2008 or above) instance to store policies
SQL Server (2008 or above) instance to act as the Central Management Server
SQL Server (2008 or above) instance to execute the PowerShell script
SQL Server management database to archive policy evaluation results
SQL Server (2008 or above) Reporting Services to render and deliver policy history reports
Please refer to Microsoft documentation (Features Supported by the Editions of SQL Server) to determine the appropriate editions to support central management server, policy evaluation, SQL Server Agent, and Reporting Services. All components are supported on SQL Server Enterprise and SQL Server Standard.
This document identifies the steps to configure the Enterprise Policy Management Framework objects in a SQL Server environment.
The EPM Framework requires an instance of SQL Server (2008 or above) designated as a Central Management Server (CMS). The CMS will manage the logical groups of servers. The names of the logical groups are passed into variables in the Enterprise Policy Management Framework for policy evaluation against these groups.
If an instance has not yet been designated as a Central Management Server, execute the following steps:
Open SQL Server Management Studio. Select the View menu. Click Registered Servers.
In Registered Servers, expand Database Engine, right-click Central Management Servers, point to New, and then click Central Management Servers.
In the New Server Registration dialog box, register the instance of SQL Server that you want to become the Central Management Server.
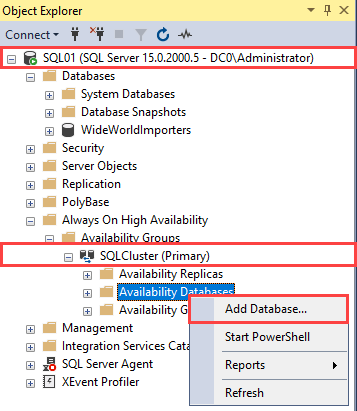
After a SQL Server (2008 or above) instance has been designated as a CMS, create the logical server groups and register SQL Server instances into these logical server group. SQL Server Books Online details the manual steps to register instances into logical server groups: Create a Central Management Server and Server Group. Figure 1 is an example of a Central Management Server (individual server groups and registered instances will differ based on each environment).
All policies that will be evaluated using the EPM framework will be stored and managed on the SQL Server instance defined as the Central Management Server. The PowerShell script will loop through these policies during execution.
Policies stored on the Central Management Server should be configured to improve execution scale and minimize/eliminate false policy failures. The following are best practices for designing policies to scale with the EPM Framework.
Categorize policies
The EPM framework PowerShell script must be given a parameter for policy category (example: Microsoft Best Practices: Performance). Therefore all policies should be placed in a category to enable a scalable solution for policy evaluation over a large environment.
Ensure all policies are configured with appropriate server restrictions and defined targets.
Policies may not be relevant for all versions and/or editions of SQL Server. For example, a policy which checks that a database is enabled for Transparent Data Encryption will not be relevant on SQL Server 2000 or SQL Server 2005, or SQL Server 2008 editions other than Enterprise. Furthermore, this policy may not be relevant for every database on an instance. A policy that checks for existing number of data files might be more relevant for tempDB only. Define server restrictions on polices to eliminate evaluation failures due to incompatible editions. Define targets on polices to eliminate false failures for databases which are not relevant to the policy.
If at a given point in time you choose to stop collecting for a specific policy that belonged to a category YY, instead of just deleting that policy (which would not clear its previous result from the reports), we recommend you move it to a new category named “Disabled”, which you would not be collecting results on that category in any job. This way, not only will you keep the policy should you choose to use it again, but also the reports will exclude that specific category and any policies inside, including historic data on any policy inside that “Disabled” category.
Environments may wish to leverage the Best Practices Policies which are installed with SQL Server (Figure 2 below shows the SQL Server 2012 Policies setup) or available from the SQL Server 2008 R2 Feature Pack. If installed already, these policies may be imported to the Central Management Server – for example, SQL Server 2012 includes pre-configured best practice policies typically located at C:\Program Files (x86)\Microsoft SQL Server\110\Tools\Policies\DatabaseEngine\1033. For further information on this topic, see How to: Export and Import a Policy-Based Management Policy.
Figure 2
If you choose to import these policies, you may want to run the script PBM_Fix_ImportedPolicies.sql afterwards for some needed actions. Please read the script notes to understand what is being changed.
The script EPM_Create_Database_Objects.sql will create the database to store the policy history, the policy schema, the tables, views, functions and stored procedure to support the framework. If installing on an instance that supports Database Compression, then Page Compression will be used in this database.
Open the SQLCMD script EPM_Create_Database_Objects.sql in SQL Server Management Studio.
Change the query execution to SQLCMD Mode. In the menu bar select Query -> SQLCMD Mode.
In the query, configure the variable ServerName with the name of the Central Management Server instance.
Configure the variable ManagementDatabase with the name of the database where the policy evaluation history will be created. See Figure 3.
Policy evaluation results will be stored in a SQL Server database designated for database management purposes. Many environments may choose to use a Management Data Warehouse created for Data Collectors, but this is not required. Sizing this database will depend on how many policies are evaluated, how many properties are evaluated in each policy, how many instances are evaluated, and how long the historical data will be maintained.
Update the EPM_EnterpriseEvaluation_4.ps1 PowerShell script variables for the enterprise environment.
Open EPM_EnterpriseEvaluation_4.ps1 in Notepad or a PowerShell script editor.
Update the variables identified below with your values. See Figure 4.
$CentralManagementServer: Required.Centralized location of the SQL Server instance where the policy evaluation history database is located. This is the instance and database where the policy evaluation results are written and policies are stored.
$HistoryDatabase: Required. Name of the history database where the policy evaluation results are written.
$ResultDir: Required. File location to write the policy evaluation results during the PowerShell execution. Results are written to this location temporarily.
# Declare variables to define the central warehouse# in which to write the output, store the policies$CentralManagementServer = “Win2012″$HistoryDatabase = “MDW”# Define the location to write the results of the policy evaluation$ResultDir = “E:\Results\”
Review the PowerShell script EPM_EnterpriseEvaluation_4.ps1. The scriptrequires three parameters. These parameters will support a granular evaluation strategy.
-ConfigurationGroup: Define the Central Management Server group to evaluate. If an empty string (“”), the PowerShell script will evaluate all servers registered in all of the CMS groups.
-PolicyCategoryFilter: Identifies which category of policies will be evaluated. If an empty string (“”), the PowerShell script will evaluate all polices stored on the Central Management Server.
-EvalMode: Specify the action to take during policy evaluation. Options are Check, Configure. Check will evaluate and report on the evaluation of the policy against the target. Configure will evaluate and report on the evaluation of the policy against the target, and reconfigure any deterministic options that are not in compliance with the policies.
To test the script prior to creating a job, open PowerShell in SQL Server Management Studio.
Open SQL Server Management Studio. Connect to the Central Management Server.
In Object Explorer, right-click on the Server and select “Start PowerShell”
Configure the following commands to your environment. Paste the commands to the SQL Server PowerShell console.
SL “Insert script folder location”.\EPM_EnterpriseEvaluation_4.ps1 -ConfigurationGroup “Insert Central Management Server Group” -PolicyCategoryFilter “Insert Policy Category” –EvalMode “Check”
When the script has completed, run the following statements against the database created in step 3. Results should appear from one or both views.
SELECT * FROM policy.v_PolicyHistoryGOSELECT * FROM policy.v_EvaluationErrorHistoryGO
Open SQL Server Management Studio. Connect to the Central Management Server. Open SQL Server Agent.
Right-click the Jobs folder and select “New Job…”.
Name the job. In the left pane select “Steps”.
Select the “New…” at the bottom.
In the New Job Step window name the Job Step. Select PowerShell from the Type drop-down.
Select the appropriate proxy account in the “Run As” drop-down. This step is required if SQL Server Agent is not running with a domain account that has elevated rights on all instances. See Use a SQL Agent Proxy for Special Tasks for details on configuring a proxy account.
Enter the following PowerShell script in the command window. Replace the sample parameter values.
After SL, place the folder location where the EPM_EnterpriseEvaluation_4 is stored from step 4. In the next line, configure the parameters with a Central Management Server Group and a Policy Category. The above is an example which will evaluate all servers in the Production Group and subgroups with the policies in the category “Microsoft Best Practices: Performance”
Select OK to save the job step. See Figure 5 for an example of the job step.
In the New Job window, select “Schedule” in the left pane. Configure the schedule to meet the evaluation requirements.
If you created one job per category, and you want several jobs to execute at once, keep in mind that some job sub systems do not allow more than 2 amount of simultaneous threads, such as the case of PowerShell. As such, you might want to update SQL Agent PowerShell simultaneous threads to a larger number, say 10, using the following example:
Note: Running the above command requires a restart of the SQL Agent on SQL Server 2008 and SQL Server 2008R2.
Note2: The above no longer works in SQL Server 2012 or above, whereas the max_worker_thread value will assume its default value of 2 after a SQL Agent restart.
After the PowerShell script was successfully executed and the results of policy evaluation were collected in the management data warehouse, it is very convenient to visualize the data through Reporting Services reports. Steps below describe the process of report configuration and deployment.
Configure the Project properties with SSRS deployment options.
Double-click ..\ 2Reporting\PolicyReports.sln to open the PolicyReports project in Visual Studio, Business Intelligence Development Studio or SQL Server Data Tools.
In the right Solution Explorer pane, right-click PolicyDW.rds in the Shared Data Sources folder and select Open.
Configure the connection string to the Central Management Server instance and database which stores the policy history. Select OK to save.
Right click on the PolicyReports project and select Properties. See Figure 6. Set the appropriate TargetServerUrl, TargetReportFolder and TargetDataSourceFolder properties of the “PolicyReports” project. These will align with the SQL Server Reporting Services instance.
The visual indicators in the Last Execution Status table and the Failed Policy % By Month chart of the PolicyDashboard report will dynamically change color (see Figure 7) based on thresholds configured in hidden parameters of the report.
Change the value to the appropriate value for your environment. The default is 0.5 which will cause the report objects to use a Red color when the failed policy average falls below 50%. Select OK to save.
Right-click PolicyThresholdCaution and select Parameter Properties.
In the Report Parameter Properties dialog, select Default Values.
Change the value to the appropriate value for your environment. The default is 0.17 which will cause the report objects to use an orange color when the failed policy average falls between 17% and 50%. Select OK to save. When the failed policy average falls between 17% a Yellow color is used.
In the right pane Solution Explorer, right-click on the PolicyReports project and select Deploy.
When polices are evaluated through PowerShell, they will execute the policy evaluation in the context of the user issuing the evaluation. This account will require access to all instances and database objects the script will evaluate. The level of permissions will depend on what the policy is evaluating. This extends to the execution account used in a scheduling agent. In SQL Server, the SQL Server Agent job step executes in the context of a specific user. This user may be a proxy account. The account that is specified in the SQL Server Agent step must have access to all objects on all instances that the PowerShell script will be evaluating.
Prior to setting up the SQL Server Agent job, be sure to set up a Proxy Account that has the appropriate rights on the remote instances to evaluate the policies. See Use a SQL Agent Proxy for Special Tasks for details on configuring a proxy account.
Archive
The data stored in the table policy.PolicyHistory is not used to report through the EPM Framework reports. Environments concerned with data space used by the EPM Framework will want to set up a regular process to purge data from this table, unless it is necessary to maintain for compliance.
Below is an example of a cycle that will purge data over 90 days, which can be used inside a SQL Agent job.
WHILE (SELECT COUNT(PolicyHistoryID) FROM MDW.policy.PolicyHistory WHERE EvaluationDateTime > DATEADD(dd, DATEDIFF(dd, 0, GETDATE()), -90)) > 0BEGIN DELETE TOP (5000) FROM MDW.policy.PolicyHistory WHERE EvaluationDateTime > DATEADD(dd, DATEDIFF(dd, 0, GETDATE()), -90)END;DELETE FROM MDW.policy.EvaluationErrorHistoryWHERE EvaluationDateTime > DATEADD(dd, DATEDIFF(dd, 0, GETDATE()), -90);GO
Execution Strategies
Prior to creating the SQL Server Agent job(s), determine the execution strategy for the EPM framework PowerShell script EPM_EnterpriseEvaluation_4.ps1 based on scale, execution time and security. Create SQL Server Agent jobs to execute the policy evaluation according to the strategy.
Administrators managing larger environments may want to implement policy evaluation through multiple parallel jobs that guarantee evaluation completion in the desired scope of time. A large environment that is challenged with a small maintenance window to execute the evaluation may design an execution strategy where the total number of concurrent jobs equals the total number of cores available for the instance.
EPM_EnterpriseEvaluation_4.ps1 may be configured with multiple SQL Server Agent jobs for each policy category and/or each group of servers.
EPM_EnterpriseEvaluation_4.ps1 may be configured with a single SQL Server Agent job and multiple steps for each policy category and/or each group of servers.
The script may also be configured to evaluate all policies against all instances (groups) by passing blank strings in as the –ConfigurationGroup and –PolicyCategoryFilter parameters. This configuration is not recommended for environments with a large number of instances and a large number of policies.
The EPM Framework version 4 supports nested server groups defined in the Central Management Server. Note in Figure 10 that the group “Production” has three nested groups. When a parent group is used as the parameter –ConfigurationGroup, all instances registered to the parent group and all instances registered to child groups will be included in the evaluation.
policy.PolicyHistory: Stores evaluation results from the PowerShell script. The XML results are shred into the table PolicyHistoryDetail. This data is not used for reporting and may be archived and/or purged as deemed necessary.
policy.PolicyHistoryDetail: Stores the shredded results from the EvaluationResults column in policy.PolicyHistory table. This table is the source for all policy result views.
policy.EvaluationErrorHistory: Stores the following types of errors:
Server connection errors
Evaluation process cannot write to the PolicyHistory table
policy.v_PolicyHistory : Returns the full historical dataset. Depends on policy.PolicyHistoryDetail.
policy.v_PolicyHistory_Rank: Ranks the policy results for each object on each server by date. Depends on policy.v_PolicyHistory.
policy.v_PolicyHistory_LastEvaluation: Returns the last execution status for each policy evaluation against each object on each server. Depends on policy.v_PolicyHistory_Rank.
policy.v_EvaluationErrorHistory: Returns all evaluation errors from the EvaluationErrorHistory table combined with the PolicyHIstoryDetail table.
policy.v_EvaluationErrorHistory_LastEvaluation: Returns the ranked errors from the v_EvaluationErrorHistory view. The last error for each evaluation is returned when the query includes a filter on EvaluationOrderDesc = 1.
policy.v_ServerGroups: Returns the server groups. Used in reports to drive parameters.
policy.epm_Load_PolicyHistoryDetail: Executed during the PowerShell evaluation. Shreds the PolicyHistory XML results and stores in policy.PolicyHistoryDetail and policy.EvaluationErrorHistory.
If upgrading from the previous version of EPM, simply execute EPM_Upgrade_Database_Objects.sql to add or change the required objects, without loss of data to your current deployment.
PowerShell Script
Replace EPM_EnterpriseEvaluation_3.0.0.ps1 with EPM_EnterpriseEvaluation_4.ps1, and change the reference in all your jobs accordingly. Refer to step 4 (Configure PowerShell Script) for further information on the script usage.
Reports
Deploy the new reports as detailed in step 7 (Deploy Reports to SQL Server
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Database2012′, @description=N”, @facet=N’Database’, @expression=N’ Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool EQ 2 Bool AutoClose Bool False Bool 0 Bool EQ 2 Bool AutoCreateStatisticsEnabled Bool True Bool 0
Bool 1 Bool OR 2 Bool OR 2 Bool EQ 2 Numeric Status Numeric Enum Numeric 2 String System.String Microsoft.SqlServer.Management.Smo.DatabaseStatus String System.String Normal Bool EQ 2 Numeric Status Numeric Enum Numeric 2 String System.String Microsoft.SqlServer.Management.Smo.DatabaseStatus String System.String Restoring Bool EQ 2 Numeric Status Numeric Enum Numeric 2 String System.String Microsoft.SqlServer.Management.Smo.DatabaseStatus String System.String Standby ‘, @is_name_condition=0, @obj_name=N”, @condition_id=@condition_id OUTPUT Select @condition_id
GO
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Database2016+’, @description=N”, @facet=N’Database’, @expression=N’ Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool EQ 2 Bool AutoClose Bool False Bool 0 Bool EQ 2 Bool AutoCreateIncrementalStatisticsEnabled Bool False Bool 0
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Server Version 2016+’, @description=N”, @facet=N’Server’, @expression=N’ Bool GE 2 Numeric VersionMajor Numeric System.Double 13 ‘, @is_name_condition=0, @obj_name=N”, @condition_id=@condition_id OUTPUT Select @condition_id
GO
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Server2008′, @description=N”, @facet=N’Server’, @expression=N’ Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool LIKE 2 String BackupDirectory String System.String G%Sqlbackup%Database% Bool LIKE 2 String ErrorLogPath String System.String D%MSSQL10%MSSQL%Log%
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Server2012′, @description=N”, @facet=N’Server’, @expression=N’ Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool LIKE 2 String BackupDirectory String System.String G%Sqlbackup%Database% Bool LIKE 2 String DefaultFile String System.String E%MSSQL11%%MSSQL%DATA%
Bool LIKE 2 String DefaultLog String System.String F%MSSQL11%%MSSQL%DATA%
Bool LIKE 2 String ErrorLogPath String System.String D%MSSQL11%MSSQL%Log%
Declare @condition_id int EXEC msdb.dbo.sp_syspolicy_add_condition @name=N’Server2016′, @description=N”, @facet=N’Server’, @expression=N’ Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool AND 2 Bool LIKE 2 String BackupDirectory String System.String G%Sqlbackup%Database% Bool LIKE 2 String DefaultFile String System.String E%MSSQL13%MSSQL%DATA%
Bool LIKE 2 String DefaultLog String System.String F%MSSQL13%MSSQL%DATA%
Bool LIKE 2 String ErrorLogPath String System.String D%MSSQL13%MSSQL%Log%
USE [master] GO / Object: Login [DBG\svc_dbDooT-SQL] Script Date: 27/05/2021 14:58:45 / CREATE LOGIN [DBG\svc_dbDooT-SQL] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO
USE [dbDooT] GO / Object: User [DBG\svc_dbDooT-SQL] Script Date: 27/05/2021 14:59:05 / CREATE USER [DBG\svc_dbDooT-SQL] FOR LOGIN [DBG\svc_dbDooT-SQL] WITH DEFAULT_SCHEMA=[dbo] GO ALTER ROLE [db_owner] ADD MEMBER [DBG\svc_dbDooT-SQL] GO
USE [msdb] GO / Object: User [DBG\svc_dbDooT-SQL] Script Date: 27/05/2021 14:59:36 / CREATE USER [DBG\svc_dbDooT-SQL] FOR LOGIN [DBG\svc_dbDooT-SQL] WITH DEFAULT_SCHEMA=[dbo] GO ALTER ROLE [db_datareader] ADD MEMBER [DBG\svc_dbDooT-SQL] GO ALTER ROLE [PolicyAdministratorRole] ADD MEMBER [DBG\svc_dbDooT-SQL] GO
Create_Job_PBM-dbDooT
USE [msdb] GO
/ Object: Job [PBM-dbDooT] Script Date: 24/06/2021 12:36:17 / BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 / Object: JobCategory [[Uncategorized (Local)]] Script Date: 24/06/2021 12:36:17 / IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]’ AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N’JOB’, @type=N’LOCAL’, @name=N'[Uncategorized (Local)]’ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback
declare @onemonthback varchar(50) set @onemonthback = dateadd (mm, -1, getdate()) declare @oneweekback varchar(50) set @oneweekback = dateadd (dd, -7, getdate())
delete from [dbDooT].[policy].[EvaluationErrorHistory] where [EvaluationDateTime] <= @onemonthback
delete from [dbDooT].[policy].[PolicyHistory] where [EvaluationDateTime] <= @onemonthback
delete from [dbDooT].[policy].[PolicyConditionResults] where [EvaluationDateTime] <= @oneweekback
GO’, @database_name=N’dbDooT’, @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N’PBM-dbDooT-Daily’, @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=1, @freq_subday_interval=0, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20210215, @active_end_date=99991231, @active_start_time=70000, @active_end_time=235959, @schedule_uid=N’46e71a88-b1b1-4bbc-be81-0637cab2435e’ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)’ IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Create_Proxy
USE [msdb] GO
/*First need to create a credential, this needs to eb a domain accoutn which has access to all SQl Servers with the following permissions, the msdb role “PolicyAdministratorRole” assigned to it */
–The following index ensures ref integrity and avoids duplicate entires. CREATE UNIQUE NONCLUSTERED INDEX [IDX_Unique] ON [policy].[PolicyConditionResults] ( [EvaluationDateTime] ASC, [EvaluatedPolicy] ASC, [EvaluatedServer] ASC, [EvaluatedObject] ASC, [EvaluatedCondition] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = ON, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
Create_Target_Login
USE [master] GO
/ Object: Login [DBG\olaftor-a] Script Date: 21/04/2021 15:00:28 / CREATE LOGIN [DBG\dbDooT-MSSQL] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO
USE [msdb] GO ALTER ROLE [PolicyAdministratorRole] ADD MEMBER [DBG\dbDooT-MSSQL] GO
EPM_Create_Database_Objects
/* SQLCMD script to generate the required objects to support a centralized Policy-Based Management solution. This is the first script to run. Set the variables to define the server and database which stores the policy results. */ :SETVAR ServerName “SYBENG01” :SETVAR ManagementDatabase “dbDooT” GO :CONNECT $(ServerName) GO
–Create the specified database if it does not exist IF NOT EXISTS(SELECT * FROM sys.databases WHERE name = ‘$(ManagementDatabase)’) CREATE DATABASE $(ManagementDatabase) GO
–Create a schema to support the EPM framework objects. USE $(ManagementDatabase) GO IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = N’policy’) EXEC sys.sp_executesql N’CREATE SCHEMA [policy] AUTHORIZATION [dbo]’
–Start create tables and indexes
–Create the table to store the results from the PowerShell evaluation. IF NOT EXISTS(SELECT * FROM sys.objects WHERE type = N’U’ AND name = N’PolicyHistory’) BEGIN CREATE TABLE [policy].[PolicyHistory]( [PolicyHistoryID] [int] IDENTITY NOT NULL , [EvaluatedServer] nvarchar NULL, [EvaluationDateTime] [datetime] NULL, [EvaluatedPolicy] nvarchar NULL, [EvaluationResults] [xml] NOT NULL, CONSTRAINT PK_PolicyHistory PRIMARY KEY CLUSTERED (PolicyHistoryID) )
ALTER TABLE [policy].[PolicyHistory] ADD CONSTRAINT [DF_PolicyHistory_EvaluationDateTime] DEFAULT (GETDATE()) FOR [EvaluationDateTime]
END GO IF EXISTS(SELECT * FROM sys.columns WHERE object_id = object_id(‘policy.policyhistory’) AND name = ‘PolicyResult’) BEGIN ALTER TABLE policy.PolicyHistory DROP COLUMN PolicyResult END GO IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistory]’) AND name = N’IX_EvaluationResults’) DROP INDEX IX_EvaluationResults ON policy.PolicyHistory GO CREATE PRIMARY XML INDEX IX_EvaluationResults ON policy.PolicyHistory (EvaluationResults) GO
CREATE XML INDEX IX_EvaluationResults_PROPERTY ON policy.PolicyHistory (EvaluationResults) USING XML INDEX IX_EvaluationResults FOR PROPERTY GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistory]’) AND name = N’IX_EvaluatedPolicy’) DROP INDEX IX_EvaluatedPolicy ON policy.PolicyHistory GO CREATE INDEX IX_EvaluatedPolicy ON policy.PolicyHistory(EvaluatedPolicy) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistory]’) AND name = N’IX_EvaluatedServer’) DROP INDEX IX_EvaluatedServer ON policy.PolicyHistory GO CREATE INDEX IX_EvaluatedServer ON [policy].PolicyHistory INCLUDE ([PolicyHistoryID],[EvaluationDateTime],[EvaluatedPolicy]) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistory]’) AND name = N’IX_EvaluationDateTime’) DROP INDEX IX_EvaluationDateTime ON policy.PolicyHistory GO CREATE INDEX IX_EvaluationDateTime ON policy.PolicyHistory (EvaluationDateTime) GO
–Create the table to store the error information from the failed PowerShell executions. IF NOT EXISTS (SELECT * FROM sys.objects WHERE type = N’U’ AND name = N’EvaluationErrorHistory’) BEGIN CREATE TABLE [policy].[EvaluationErrorHistory]( [ErrorHistoryID] [int] IDENTITY(1,1) NOT NULL, [EvaluatedServer] nvarchar NULL, [EvaluationDateTime] [datetime] NULL, [EvaluatedPolicy] nvarchar NULL, [EvaluationResults] nvarchar NOT NULL, CONSTRAINT PK_EvaluationErrorHistory PRIMARY KEY CLUSTERED ([ErrorHistoryID] ASC) )
ALTER TABLE [policy].[EvaluationErrorHistory] ADD CONSTRAINT [DF_EvaluationErrorHistory_EvaluationDateTime] DEFAULT (getdate()) FOR [EvaluationDateTime]
END
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = N’IX_EvaluationErrorHistoryView’) DROP INDEX IX_EvaluationErrorHistoryView ON policy.EvaluationErrorHistory GO CREATE INDEX [IX_EvaluationErrorHistoryView] ON policy.EvaluationErrorHistory ([EvaluatedPolicy] ASC, [EvaluatedServer] ASC, [EvaluationDateTime] DESC) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = N’IX_EvaluationErrorHistoryPurge’) DROP INDEX IX_EvaluationErrorHistoryPurge ON policy.EvaluationErrorHistory GO CREATE INDEX [IX_EvaluationErrorHistoryPurge] ON policy.EvaluationErrorHistory ([EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer] GO CREATE STATISTICS [Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer] ON [policy].[EvaluationErrorHistory]([EvaluatedPolicy], [ErrorHistoryID], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedServer_EvaluationDateTime] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime]) GO
–Create the table to store the policy result details. –This table is loaded with the procedure policy.epm_LoadPolicyHistoryDetail or through the SQL Server SSIS policy package. IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND type in (N’U’)) BEGIN CREATE TABLE [policy].[PolicyHistoryDetail]( [PolicyHistoryDetailID] [int] IDENTITY NOT NULL, [PolicyHistoryID] [int] NULL, [EvaluatedServer] nvarchar NULL, [EvaluationDateTime] [datetime] NULL, [MonthYear] nvarchar NULL, [EvaluatedPolicy] nvarchar NULL, [policy_id] [int] NULL, [CategoryName] nvarchar NULL, [EvaluatedObject] nvarchar NULL, [PolicyResult] nvarchar NOT NULL, [ExceptionMessage] nvarchar NULL, [ResultDetail] [xml] NULL, [PolicyHistorySource] nvarchar NOT NULL, CONSTRAINT PK_PolicyHistoryDetail PRIMARY KEY CLUSTERED ([PolicyHistoryDetailID]) ) END GO
ALTER TABLE policy.PolicyHistoryDetail ADD CONSTRAINT FK_PolicyHistoryDetail_PolicyHistory FOREIGN KEY (PolicyHistoryID) REFERENCES policy.PolicyHistory (PolicyHistoryID) ON UPDATE CASCADE ON DELETE CASCADE GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’FK_PolicyHistoryID’) DROP INDEX FK_PolicyHistoryID ON policy.PolicyHistoryDetail GO CREATE INDEX FK_PolicyHistoryID ON [policy].PolicyHistoryDetail GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedPolicy’) DROP INDEX IX_EvaluatedPolicy ON policy.PolicyHistoryDetail GO CREATE INDEX IX_EvaluatedPolicy ON [policy].PolicyHistoryDetail INCLUDE ([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [MonthYear], [policy_id], [CategoryName], [EvaluatedObject], [PolicyResult]) GO IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_PolicyHistoryView’) DROP INDEX IX_PolicyHistoryView ON policy.PolicyHistoryDetail GO CREATE INDEX [IX_PolicyHistoryView] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy] ASC, [EvaluatedServer] ASC, [EvaluatedObject] ASC, [EvaluationDateTime] DESC, [PolicyResult] ASC, [policy_id] ASC, CategoryName, MonthYear) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_PolicyHistoryView_2′) DROP INDEX IX_PolicyHistoryView_2 ON policy.PolicyHistoryDetail GO CREATE INDEX [IX_PolicyHistoryView_2] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy] ASC ,[EvaluatedServer] ASC ,[EvaluationDateTime] ASC) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime’) DROP INDEX IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime ON policy.PolicyHistoryDetail GO CREATE INDEX [IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime] ON [policy].[PolicyHistoryDetail] ([EvaluatedServer] ASC, [EvaluatedPolicy] ASC, [EvaluatedObject] ASC, [EvaluationDateTime] ASC) INCLUDE ([PolicyResult]) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedPolicy_MonthYear’) DROP INDEX IX_EvaluatedPolicy_MonthYear ON policy.PolicyHistoryDetail GO CREATE INDEX IX_EvaluatedPolicy_MonthYear ON [policy].PolicyHistoryDetail INCLUDE (EvaluationDateTime) GO
–CREATE INDEX IX_CategoryName_EvaluatedPolicy ON [policy].PolicyHistoryDetail –GO
–CREATE INDEX IX_EvaluatedPolicy_CategoryName ON [policy].PolicyHistoryDetail –GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedPolicy_EvalDateTime_CategoryName’) DROP INDEX IX_EvaluatedPolicy_EvalDateTime_CategoryName ON policy.PolicyHistoryDetail GO CREATE INDEX IX_EvaluatedPolicy_EvalDateTime_CategoryName ON [policy].PolicyHistoryDetail INCLUDE ([PolicyHistoryDetailID],[MonthYear],[PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail] ([EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_EvaluatedServer’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_EvaluatedServer] GO CREATE STATISTICS [Stat_CategoryName_EvaluatedServer] ON [policy].[PolicyHistoryDetail] ([CategoryName], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyResult_EvaluatedServer’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyResult_EvaluatedServer] GO CREATE STATISTICS [Stat_PolicyResult_EvaluatedServer] ON [policy].[PolicyHistoryDetail] ([PolicyResult], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [EvaluatedServer], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_PolicyResult_CategoryName’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_PolicyResult_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_PolicyResult_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [PolicyResult], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime], [PolicyResult], [PolicyHistoryID], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_PolicyResult] GO CREATE STATISTICS Stat_CategoryName_PolicyResult ON [policy].[PolicyHistoryDetail]([CategoryName], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy] GO CREATE STATISTICS Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [PolicyHistoryDetailID], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime] GO CREATE STATISTICS Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [CategoryName], [PolicyResult], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult] GO CREATE STATISTICS Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluatedServer], [PolicyHistoryDetailID], [CategoryName], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID] GO CREATE STATISTICS Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [CategoryName], [PolicyResult], [EvaluatedPolicy], [EvaluationDateTime], [PolicyHistoryDetailID]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([CategoryName], [EvaluatedPolicy], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [EvaluatedObject], [EvaluationDateTime], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [PolicyHistoryDetailID], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy], [PolicyHistoryDetailID], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer] GO CREATE STATISTICS [Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer] ON [policy].[PolicyHistoryDetail]([PolicyResult], [EvaluatedPolicy], [PolicyHistoryDetailID], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([PolicyHistoryDetailID], [PolicyHistoryID], [EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [policy_id]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID] ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [policy_id], [CategoryName], [PolicyHistoryID]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [PolicyResult], [EvaluatedServer], [EvaluationDateTime], [PolicyHistoryDetailID], [policy_id], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluatedServer], [PolicyResult], [EvaluationDateTime], [PolicyHistoryDetailID], [PolicyHistoryID], [policy_id], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [CategoryName]) GO
–Create the function to support server selection. –The following function will support nested CMS folders for the EPM Framework. –The function must be created in a database ON the CMS server. –This database will also store the policy history.
USE $(ManagementDatabase) GO IF EXISTS(SELECT * FROM sys.objects WHERE name = ‘pfn_ServerGroupInstances’ AND type = ‘TF’) DROP FUNCTION policy.pfn_ServerGroupInstances GO CREATE FUNCTION [policy].[pfn_ServerGroupInstances] (@server_group_name NVARCHAR(128)) RETURNS TABLE AS RETURN(WITH ServerGroups(parent_id, server_group_id, name) AS ( SELECT parent_id, server_group_id, name FROM msdb.dbo.sysmanagement_shared_server_groups tg WHERE is_system_object = 0 AND (tg.name = @server_group_name OR @server_group_name = ”) UNION ALL SELECT cg.parent_id, cg.server_group_id, cg.name FROM msdb.dbo.sysmanagement_shared_server_groups cg INNER JOIN ServerGroups pg ON cg.parent_id = pg.server_group_id ) SELECT s.server_name, sg.name AS GroupName FROM [msdb].[dbo].[sysmanagement_shared_registered_servers_internal] s INNER JOIN ServerGroups SG ON s.server_group_id = sg.server_group_id ) GO /* CREATE FUNCTION policy.pfn_ServerGroupInstances (@server_group_name NVARCHAR(128)) RETURNS @ServerGroups TABLE (server_name nvarchar(128), GroupName nvarchar(128)) AS BEGIN IF @server_group_name = ” BEGIN INSERT @ServerGroups SELECT s.server_name, ssg.name AS GroupName FROM [msdb].[dbo].[sysmanagement_shared_registered_servers_internal] s INNER JOIN msdb.dbo.sysmanagement_shared_server_groups ssg ON s.server_group_id = ssg.server_group_id END ELSE WITH ServerGroups(parent_id, server_group_id, name) AS ( SELECT parent_id, server_group_id, name FROM msdb.dbo.sysmanagement_shared_server_groups tg WHERE is_system_object = 0 AND (tg.name = @server_group_name OR @server_group_name = ”) UNION ALL SELECT cg.parent_id, cg.server_group_id, cg.name FROM msdb.dbo.sysmanagement_shared_server_groups cg INNER JOIN ServerGroups pg ON cg.parent_id = pg.server_group_id ) INSERT @ServerGroups SELECT s.server_name, sg.name AS GroupName FROM [msdb].[dbo].[sysmanagement_shared_registered_servers_internal] s INNER JOIN ServerGroups SG ON s.server_group_id = sg.server_group_id RETURN END GO */
–Create the views which are used in the policy reports
–Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_ServerGroups]’)) DROP VIEW [policy].[v_ServerGroups] GO CREATE VIEW policy.v_ServerGroups AS WITH ServerGroups(parent_id, server_group_id, GroupName, GroupLevel, Sort, GroupValue) AS (SELECT parent_id , server_group_id , CAST(‘ALL’ AS varchar(500)) , 1 AS GroupLevel , CAST(‘ALL’ AS varchar(500)) AS Sort , CAST(” AS varchar(255)) AS GroupValue FROM msdb.dbo.sysmanagement_shared_server_groups tg WHERE server_type = 0 AND parent_id IS NULL UNION ALL SELECT cg.parent_id , cg.server_group_id , CAST(REPLICATE(‘ ‘, GroupLevel) + cg.name AS varchar(500)) , GroupLevel + 1 , CAST(Sort + ‘ | ‘ + cg.name AS varchar(500)) AS Sort , CAST(name AS varchar(255)) AS GroupValue FROM msdb.dbo.sysmanagement_shared_server_groups cg INNER JOIN ServerGroups pg ON cg.parent_id = pg.server_group_id)
SELECT parent_id, server_group_id, GroupName, GroupLevel, Sort, GroupValue FROM ServerGroups GO
–Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory]’)) DROP VIEW [policy].[v_PolicyHistory] GO CREATE VIEW [policy].[v_PolicyHistory] AS –The policy.v_PolicyHistory view will return all results –and identify the policy evaluation result AS PASS, FAIL, or –ERROR. The ERROR result indicates that the policy was not able –to evaluate against an object. SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , PH.PolicyResult , PH.ExceptionMessage , PH.ResultDetail , PH.EvaluatedObject , PH.policy_id , PH.CategoryName , PH.MonthYear FROM policy.PolicyHistoryDetail PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy –INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id AND PH.EvaluatedPolicy NOT IN (SELECT spp.name FROM msdb.dbo.syspolicy_policies spp INNER JOIN msdb.dbo.syspolicy_policy_categories spc ON spp.policy_category_id = spc.policy_category_id WHERE spc.name = ‘Disabled’) GO
–Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory_Rank]’)) DROP VIEW policy.v_PolicyHistory_Rank GO CREATE VIEW policy.v_PolicyHistory_Rank AS SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ResultDetail , ExceptionMessage , policy_id , CategoryName , MonthYear , DENSE_RANK() OVER ( PARTITION BY EvaluatedPolicy, EvaluatedServer, EvaluatedObject ORDER BY EvaluationDateTime DESC) AS EvaluationOrderDesc FROM policy.v_PolicyHistory VPH GO
–Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory_LastEvaluation]’)) DROP VIEW policy.v_PolicyHistory_LastEvaluation GO CREATE VIEW policy.v_PolicyHistory_LastEvaluation AS –The policy.v_PolicyHistory_LastEvaluation view will the last result for any given policy evaluated against an object. –This view requires the v_PolicyHistory view exist. SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ResultDetail , ExceptionMessage , policy_id , CategoryName , MonthYear , EvaluationOrderDesc FROM policy.v_PolicyHistory_Rank VPH WHERE EvaluationOrderDesc = 1 AND NOT EXISTS( SELECT * FROM policy.PolicyHistoryDetail PH WHERE PH.EvaluatedPolicy = VPH.EvaluatedPolicy AND PH.EvaluatedServer = VPH.EvaluatedServer AND PH.EvaluationDateTime > VPH.EvaluationDateTime) GO
–Create a view to return all errors. –Errors will be returned from the table EvaluationErrorHistory and the errors in the PolicyHistory table. –Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_EvaluationErrorHistory]’)) DROP VIEW policy.v_EvaluationErrorHistory GO CREATE VIEW policy.v_EvaluationErrorHistory AS SELECT EEH.ErrorHistoryID , EEH.EvaluatedServer , EEH.EvaluationDateTime , EEH.EvaluatedPolicy , CASE WHEN CHARINDEX(‘\’, EEH.EvaluatedServer) > 0 THEN RIGHT(EEH.EvaluatedServer, CHARINDEX(‘\’, REVERSE(EEH.EvaluatedServer)) – 1) ELSE EEH.EvaluatedServer END AS EvaluatedObject , EEH.EvaluationResults , p.policy_id , c.name AS CategoryName , DATENAME(month, EvaluationDateTime) + ‘ ‘ + datename(year, EvaluationDateTime) AS MonthYear , ‘ERROR’ AS PolicyResult FROM policy.EvaluationErrorHistory AS EEH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = EEH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id UNION ALL SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , CASE WHEN EvaluatedObject != ‘No Targets Found’ THEN RIGHT(EvaluatedObject, CHARINDEX(‘\’, REVERSE(EvaluatedObject)) – 1) ELSE EvaluatedObject END AS EvaluatedObject , ExceptionMessage , policy_id , CategoryName , MonthYear , PolicyResult FROM policy.v_PolicyHistory_LastEvaluation WHERE PolicyResult = ‘ERROR’ GO
–Create a view to return the last error for each policy against –an instance. –Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_EvaluationErrorHistory_LastEvaluation]’)) DROP VIEW policy.v_EvaluationErrorHistory_LastEvaluation GO CREATE VIEW policy.v_EvaluationErrorHistory_LastEvaluation AS SELECT ErrorHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , Policy_ID , EvaluatedObject , EvaluationResults , CategoryName , MonthYear , PolicyResult , DENSE_RANK() OVER ( PARTITION BY EvaluatedServer, EvaluatedPolicy ORDER BY EvaluationDateTime DESC)AS EvaluationOrderDesc FROM policy.v_EvaluationErrorHistory EEH WHERE NOT EXISTS ( SELECT * FROM policy.PolicyHistoryDetail PH WHERE PH.EvaluatedPolicy = EEH.EvaluatedPolicy AND PH.EvaluatedServer = EEH.EvaluatedServer AND PH.EvaluationDateTime > EEH.EvaluationDateTime) GO
–Create the procedure epm_LoadPolicyHistoryDetail will load the details from the XML documents in PolicyHistory to the PolicyHistoryDetails table. IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[policy].[epm_LoadPolicyHistoryDetail]’) AND type in (N’P’, N’PC’)) DROP PROCEDURE [policy].[epm_LoadPolicyHistoryDetail] GO CREATE PROCEDURE policy.epm_LoadPolicyHistoryDetail @PolicyCategoryFilter VARCHAR(255) AS SET NOCOUNT ON;
IF @PolicyCategoryFilter = ” SET @PolicyCategoryFilter = NULL
DECLARE @sqlcmd VARCHAR(8000), @Text NVARCHAR(255), @Remain int SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting data integration for ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ‘ALL categories’ ELSE ‘Category ‘ + @PolicyCategoryFilter END RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the evaluation results. SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) ,cteEval AS (SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , Res.Expr.value(”(../DMF:TargetQueryExpression)[1]”, ”nvarchar(150)”) AS EvaluatedObject , (CASE WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”) = ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) = ”” THEN ”FAIL” WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) <> ”” THEN ”ERROR” ELSE ”PASS” END) AS PolicyResult , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage , CAST(Expr.value(”(../DMF:ResultDetail)[1]”, ”nvarchar(max)”)AS XML) AS ResultDetail , p.policy_id , c.name AS CategoryName , datename(month, EvaluationDateTime) + ” ” + datename(year, EvaluationDateTime) AS MonthYear , ”PowerShell EPM Framework” AS PolicyHistorySource , DENSE_RANK() OVER (PARTITION BY Res.Expr.value(”(../DMF:TargetQueryExpression)[1]”, ”nvarchar(150)”) ORDER BY Expr) AS [TopRank] FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //TargetQueryExpression” ) AS Res(Expr) WHERE NOT EXISTS (SELECT DISTINCT PHD.PolicyHistoryID FROM policy.PolicyHistoryDetail PHD WITH(NOLOCK) WHERE PHD.PolicyHistoryID = PH.PolicyHistoryID AND PHD.ResultDetail IS NOT NULL) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND EvaluationResults.exist(”declare namespace DMF=”http://schemas.microsoft.com/sqlserver/DMF/2007/08″; //DMF:EvaluationDetail”) = 1) INSERT INTO policy.PolicyHistoryDetail ( PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource ) SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource FROM cteEval WHERE cteEval.[TopRank] = 1′; — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting no target data integration’ RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the policies that evaluated with no target SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) INSERT INTO policy.PolicyHistoryDetail ( PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource ) SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , ”No Targets Found” AS EvaluatedObject , (CASE WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) = ”” THEN ”FAIL” WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”)<> ”” THEN ”ERROR” ELSE ”PASS” END) AS PolicyResult , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage , NULL AS ResultDetail , p.policy_id , c.name AS CategoryName , datename(month, EvaluationDateTime) + ” ” + datename(year, EvaluationDateTime) AS MonthYear , ”PowerShell EPM Framework” FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //DMF:ServerInstance” ) AS Res(Expr) WHERE NOT EXISTS (SELECT DISTINCT PHD.PolicyHistoryID FROM policy.PolicyHistoryDetail PHD WITH(NOLOCK) WHERE PHD.PolicyHistoryID = PH.PolicyHistoryID AND PHD.ResultDetail IS NULL) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND EvaluationResults.exist(”declare namespace DMF=”http://schemas.microsoft.com/sqlserver/DMF/2007/08″; //DMF:EvaluationDetail”) = 0 ORDER BY DENSE_RANK() OVER (ORDER BY Expr);’ — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting errors data integration’ RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the error records SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) INSERT INTO policy.EvaluationErrorHistory( EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluationResults ) SELECT PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //DMF:ServerInstance” ) AS Res(Expr) WHERE PH.PolicyHistoryID NOT IN (SELECT DISTINCT PH.PolicyHistoryID FROM policy.EvaluationErrorHistory AS PHD WITH(NOLOCK) INNER JOIN policy.PolicyHistory AS PH WITH(NOLOCK) ON PH.EvaluatedServer = PHD.EvaluatedServer AND PH.EvaluationDateTime = PHD.EvaluationDateTime AND PH.EvaluatedPolicy = PHD.EvaluatedPolicy) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) <> ”” –AND Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”) = ”FALSE” ORDER BY DENSE_RANK() OVER (ORDER BY Expr);’ — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Finished data integration for ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ‘ALL categories’ ELSE ‘Category ‘ + @PolicyCategoryFilter END RAISERROR (@Text, 10, 1) WITH NOWAIT; GO
USE $(ManagementDatabase) GO EXEC policy.epm_LoadPolicyHistoryDetail NULL GO
USE $(ManagementDatabase) GO IF (SELECT SERVERPROPERTY(‘EditionID’)) IN (1804890536, 1872460670, 610778273, -2117995310) — Supports Enterprise only features BEGIN ALTER INDEX [PK_EvaluationErrorHistory] ON [policy].[EvaluationErrorHistory] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) ALTER INDEX [PK_PolicyHistoryDetail] ON [policy].[PolicyHistoryDetail] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) ALTER INDEX [PK_PolicyHistory] ON [policy].[PolicyHistory] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) END; GO
EPM_Upgrade_Database_Objects
/* SQLCMD script to upgrade changed objects from previous deployment of a centralized Policy-Based Management solution. Set the variables to define the server and database which stores the policy results. */ :SETVAR ServerName “SYBENG01” :SETVAR ManagementDatabase “dbDooT” GO :CONNECT $(ServerName) GO
–Drop old indexes and stats IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedServer’) DROP INDEX IX_EvaluatedServer ON policy.PolicyHistoryDetail GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyResult] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_Policy_Server_Category’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_Policy_Server_Category] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_Policy_Result_Server’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_Policy_Result_Server] GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_Covered’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_Covered] GO
–Start create new indexes and stats IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistory]’) AND name = N’IX_EvaluationDateTime’) DROP INDEX IX_EvaluationDateTime ON policy.PolicyHistory GO CREATE INDEX IX_EvaluationDateTime ON policy.PolicyHistory (EvaluationDateTime) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = N’IX_EvaluationErrorHistoryPurge’) DROP INDEX IX_EvaluationErrorHistoryPurge ON policy.EvaluationErrorHistory GO CREATE INDEX [IX_EvaluationErrorHistoryPurge] ON policy.EvaluationErrorHistory ([EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer] GO CREATE STATISTICS [Stat_EvaluatedPolicy_ErrorHistoryID_EvaluatedServer] ON [policy].[EvaluationErrorHistory]([EvaluatedPolicy], [ErrorHistoryID], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedServer_EvaluationDateTime] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[EvaluationErrorHistory]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[EvaluationErrorHistory].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_ErrorHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] ON [policy].[EvaluationErrorHistory]([ErrorHistoryID], [EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime]) GO
ALTER TABLE policy.PolicyHistoryDetail ADD CONSTRAINT FK_PolicyHistoryDetail_PolicyHistory FOREIGN KEY (PolicyHistoryID) REFERENCES policy.PolicyHistory (PolicyHistoryID) ON UPDATE CASCADE ON DELETE CASCADE GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’FK_PolicyHistoryID’) DROP INDEX FK_PolicyHistoryID ON policy.PolicyHistoryDetail GO CREATE INDEX FK_PolicyHistoryID ON [policy].PolicyHistoryDetail GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_PolicyHistoryView_2′) DROP INDEX IX_PolicyHistoryView_2 ON policy.PolicyHistoryDetail GO CREATE INDEX [IX_PolicyHistoryView_2] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy] ASC ,[EvaluatedServer] ASC ,[EvaluationDateTime] ASC) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime’) DROP INDEX IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime ON policy.PolicyHistoryDetail GO CREATE INDEX [IX_EvaluatedServer_EvaluatedPolicy_EvaluatedObject_EvaluationDateTime] ON [policy].[PolicyHistoryDetail] ([EvaluatedServer] ASC, [EvaluatedPolicy] ASC, [EvaluatedObject] ASC, [EvaluationDateTime] ASC) INCLUDE ([PolicyResult]) GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedPolicy_MonthYear’) DROP INDEX IX_EvaluatedPolicy_MonthYear ON policy.PolicyHistoryDetail GO CREATE INDEX IX_EvaluatedPolicy_MonthYear ON [policy].PolicyHistoryDetail INCLUDE (EvaluationDateTime) GO
–CREATE INDEX IX_CategoryName_EvaluatedPolicy ON [policy].PolicyHistoryDetail –GO
–CREATE INDEX IX_EvaluatedPolicy_CategoryName ON [policy].PolicyHistoryDetail –GO
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = N’IX_EvaluatedPolicy_EvalDateTime_CategoryName’) DROP INDEX IX_EvaluatedPolicy_EvalDateTime_CategoryName ON policy.PolicyHistoryDetail GO CREATE INDEX IX_EvaluatedPolicy_EvalDateTime_CategoryName ON [policy].PolicyHistoryDetail INCLUDE ([PolicyHistoryDetailID],[MonthYear],[PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail] ([EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_EvaluatedServer’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_EvaluatedServer] GO CREATE STATISTICS [Stat_CategoryName_EvaluatedServer] ON [policy].[PolicyHistoryDetail] ([CategoryName], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyResult_EvaluatedServer’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyResult_EvaluatedServer] GO CREATE STATISTICS [Stat_PolicyResult_EvaluatedServer] ON [policy].[PolicyHistoryDetail] ([PolicyResult], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [EvaluatedServer], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_PolicyResult_CategoryName’) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_PolicyResult_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_PolicyResult_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [PolicyResult], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyResult_PolicyHistoryID_CategoryName] ON [policy].[PolicyHistoryDetail] ([EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime], [PolicyResult], [PolicyHistoryID], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_PolicyResult] GO CREATE STATISTICS Stat_CategoryName_PolicyResult ON [policy].[PolicyHistoryDetail]([CategoryName], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy] GO CREATE STATISTICS Stat_EvaluatedServer_PolicyHistoryDetailID_EvaluatedPolicy ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [PolicyHistoryDetailID], [EvaluatedPolicy]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime] GO CREATE STATISTICS Stat_EvaluatedPolicy_CategoryName_PolicyResult_EvaluationDateTime ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [CategoryName], [PolicyResult], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult] GO CREATE STATISTICS Stat_EvaluatedPolicy_EvaluatedServer_PolicyHistoryDetailID_CategoryName_PolicyResult ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluatedServer], [PolicyHistoryDetailID], [CategoryName], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID] GO CREATE STATISTICS Stat_EvaluatedServer_CategoryName_PolicyResult_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [CategoryName], [PolicyResult], [EvaluatedPolicy], [EvaluationDateTime], [PolicyHistoryDetailID]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] GO CREATE STATISTICS [Stat_CategoryName_EvaluatedPolicy_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([CategoryName], [EvaluatedPolicy], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_CategoryName] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluatedServer_EvaluationDateTime_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [EvaluatedObject], [EvaluationDateTime], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_EvaluatedPolicy_1_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [PolicyHistoryDetailID], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy_PolicyHistoryDetailID_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy], [PolicyHistoryDetailID], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer] GO CREATE STATISTICS [Stat_PolicyResult_EvaluatedPolicy_PolicyHistoryDetailID_EvaluatedServer] ON [policy].[PolicyHistoryDetail]([PolicyResult], [EvaluatedPolicy], [PolicyHistoryDetailID], [EvaluatedServer]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] GO CREATE STATISTICS [Stat_PolicyHistoryDetailID_PolicyHistoryID_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime] ON [policy].[PolicyHistoryDetail]([PolicyHistoryDetailID], [PolicyHistoryID], [EvaluatedPolicy], [EvaluatedServer], [EvaluationDateTime]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [policy_id]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID] GO CREATE STATISTICS [Stat_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_policy_id_CategoryName_PolicyHistoryID] ON [policy].[PolicyHistoryDetail]([EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [policy_id], [CategoryName], [PolicyHistoryID]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedPolicy_EvaluatedServer_EvaluationDateTime_PolicyHistoryDetailID_policy_id_CategoryName] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [PolicyResult], [EvaluatedServer], [EvaluationDateTime], [PolicyHistoryDetailID], [policy_id], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID] GO CREATE STATISTICS [Stat_EvaluatedPolicy_EvaluatedServer_EvaluatedPolicy_EvaluationDateTime_PolicyHistoryDetailID_PolicyHistoryID] ON [policy].[PolicyHistoryDetail]([EvaluatedPolicy], [EvaluatedServer], [PolicyResult], [EvaluationDateTime], [PolicyHistoryDetailID], [PolicyHistoryID], [policy_id], [CategoryName]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult] GO CREATE STATISTICS [Stat_EvaluationDateTime_EvaluatedPolicy_PolicyResult] ON [policy].[PolicyHistoryDetail]([EvaluationDateTime], [EvaluatedPolicy], [PolicyResult]) GO
IF EXISTS(SELECT * FROM sys.stats WHERE object_id = OBJECT_ID(N'[policy].[PolicyHistoryDetail]’) AND name = ‘Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName’ ) DROP STATISTICS policy.[PolicyHistoryDetail].[Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName] GO CREATE STATISTICS [Stat_PolicyHistoryID_EvaluatedServer_EvaluationDateTime_EvaluatedPolicy_CategoryName] ON [policy].[PolicyHistoryDetail]([PolicyHistoryID], [EvaluatedServer], [EvaluationDateTime], [EvaluatedPolicy], [CategoryName]) GO
–Update the function to support server selection. –The following function will support nested CMS folders for the EPM Framework. –The function must be created in a database ON the CMS server. –This database will also store the policy history.
USE $(ManagementDatabase) GO IF EXISTS(SELECT * FROM sys.objects WHERE name = ‘pfn_ServerGroupInstances’ AND type = ‘TF’) DROP FUNCTION policy.pfn_ServerGroupInstances GO CREATE FUNCTION [policy].[pfn_ServerGroupInstances] (@server_group_name NVARCHAR(128)) RETURNS TABLE AS RETURN(WITH ServerGroups(parent_id, server_group_id, name) AS ( SELECT parent_id, server_group_id, name FROM msdb.dbo.sysmanagement_shared_server_groups tg WHERE is_system_object = 0 AND (tg.name = @server_group_name OR @server_group_name = ”) UNION ALL SELECT cg.parent_id, cg.server_group_id, cg.name FROM msdb.dbo.sysmanagement_shared_server_groups cg INNER JOIN ServerGroups pg ON cg.parent_id = pg.server_group_id ) SELECT s.server_name, sg.name AS GroupName FROM [msdb].[dbo].[sysmanagement_shared_registered_servers_internal] s INNER JOIN ServerGroups SG ON s.server_group_id = sg.server_group_id ) GO
–Update the views which are used in the policy reports
IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_ServerGroups]’)) DROP VIEW [policy].[v_ServerGroups] GO CREATE VIEW policy.v_ServerGroups AS WITH ServerGroups(parent_id, server_group_id, GroupName, GroupLevel, Sort, GroupValue) AS (SELECT parent_id , server_group_id , CAST(‘ALL’ AS varchar(500)) , 1 AS GroupLevel , CAST(‘ALL’ AS varchar(500)) AS Sort , CAST(” AS varchar(255)) AS GroupValue FROM msdb.dbo.sysmanagement_shared_server_groups tg WHERE server_type = 0 AND parent_id IS NULL UNION ALL SELECT cg.parent_id , cg.server_group_id , CAST(REPLICATE(‘ ‘, GroupLevel) + cg.name AS varchar(500)) , GroupLevel + 1 , CAST(Sort + ‘ | ‘ + cg.name AS varchar(500)) AS Sort , CAST(name AS varchar(255)) AS GroupValue FROM msdb.dbo.sysmanagement_shared_server_groups cg INNER JOIN ServerGroups pg ON cg.parent_id = pg.server_group_id)
SELECT parent_id, server_group_id, GroupName, GroupLevel, Sort, GroupValue FROM ServerGroups GO
IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory]’)) DROP VIEW [policy].[v_PolicyHistory] GO CREATE VIEW [policy].[v_PolicyHistory] AS –The policy.v_PolicyHistory view will return all results –and identify the policy evaluation result AS PASS, FAIL, or –ERROR. The ERROR result indicates that the policy was not able –to evaluate against an object. SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , PH.PolicyResult , PH.ExceptionMessage , PH.ResultDetail , PH.EvaluatedObject , PH.policy_id , PH.CategoryName , PH.MonthYear FROM policy.PolicyHistoryDetail PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy –INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id AND PH.EvaluatedPolicy NOT IN (SELECT spp.name FROM msdb.dbo.syspolicy_policies spp INNER JOIN msdb.dbo.syspolicy_policy_categories spc ON spp.policy_category_id = spc.policy_category_id WHERE spc.name = ‘Disabled’) GO
IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory_Rank]’)) DROP VIEW policy.v_PolicyHistory_Rank GO CREATE VIEW policy.v_PolicyHistory_Rank AS SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ResultDetail , ExceptionMessage , policy_id , CategoryName , MonthYear , DENSE_RANK() OVER ( PARTITION BY EvaluatedPolicy, EvaluatedServer, EvaluatedObject ORDER BY EvaluationDateTime DESC) AS EvaluationOrderDesc FROM policy.v_PolicyHistory VPH GO
IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_PolicyHistory_LastEvaluation]’)) DROP VIEW policy.v_PolicyHistory_LastEvaluation GO CREATE VIEW policy.v_PolicyHistory_LastEvaluation AS –The policy.v_PolicyHistory_LastEvaluation view will the last result for any given policy evaluated against an object. –This view requires the v_PolicyHistory view exist. SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ResultDetail , ExceptionMessage , policy_id , CategoryName , MonthYear , EvaluationOrderDesc FROM policy.v_PolicyHistory_Rank VPH WHERE EvaluationOrderDesc = 1 AND NOT EXISTS( SELECT * FROM policy.PolicyHistoryDetail PH WHERE PH.EvaluatedPolicy = VPH.EvaluatedPolicy AND PH.EvaluatedServer = VPH.EvaluatedServer AND PH.EvaluationDateTime > VPH.EvaluationDateTime) GO
–Create a view to return all errors. –Errors will be returned from the table EvaluationErrorHistory and the errors in the PolicyHistory table. –Drop the view if it exists. IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_EvaluationErrorHistory]’)) DROP VIEW policy.v_EvaluationErrorHistory GO CREATE VIEW policy.v_EvaluationErrorHistory AS SELECT EEH.ErrorHistoryID , EEH.EvaluatedServer , EEH.EvaluationDateTime , EEH.EvaluatedPolicy , CASE WHEN CHARINDEX(‘\’, EEH.EvaluatedServer) > 0 THEN RIGHT(EEH.EvaluatedServer, CHARINDEX(‘\’, REVERSE(EEH.EvaluatedServer)) – 1) ELSE EEH.EvaluatedServer END AS EvaluatedObject , EEH.EvaluationResults , p.policy_id , c.name AS CategoryName , DATENAME(month, EvaluationDateTime) + ‘ ‘ + datename(year, EvaluationDateTime) AS MonthYear , ‘ERROR’ AS PolicyResult FROM policy.EvaluationErrorHistory AS EEH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = EEH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id UNION ALL SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , CASE WHEN EvaluatedObject != ‘No Targets Found’ THEN RIGHT(EvaluatedObject, CHARINDEX(‘\’, REVERSE(EvaluatedObject)) – 1) ELSE EvaluatedObject END AS EvaluatedObject , ExceptionMessage , policy_id , CategoryName , MonthYear , PolicyResult FROM policy.v_PolicyHistory_LastEvaluation WHERE PolicyResult = ‘ERROR’ GO
IF EXISTS (SELECT * FROM sys.views WHERE object_id = OBJECT_ID(N'[policy].[v_EvaluationErrorHistory_LastEvaluation]’)) DROP VIEW policy.v_EvaluationErrorHistory_LastEvaluation GO CREATE VIEW policy.v_EvaluationErrorHistory_LastEvaluation AS SELECT ErrorHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , Policy_ID , EvaluatedObject , EvaluationResults , CategoryName , MonthYear , PolicyResult , DENSE_RANK() OVER ( PARTITION BY EvaluatedServer, EvaluatedPolicy ORDER BY EvaluationDateTime DESC)AS EvaluationOrderDesc FROM policy.v_EvaluationErrorHistory EEH WHERE NOT EXISTS ( SELECT * FROM policy.PolicyHistoryDetail PH WHERE PH.EvaluatedPolicy = EEH.EvaluatedPolicy AND PH.EvaluatedServer = EEH.EvaluatedServer AND PH.EvaluationDateTime > EEH.EvaluationDateTime) GO
–Update the procedure epm_LoadPolicyHistoryDetail will load the details from the XML documents in PolicyHistory to the PolicyHistoryDetails table. IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[policy].[epm_LoadPolicyHistoryDetail]’) AND type in (N’P’, N’PC’)) DROP PROCEDURE [policy].[epm_LoadPolicyHistoryDetail] GO CREATE PROCEDURE policy.epm_LoadPolicyHistoryDetail @PolicyCategoryFilter VARCHAR(255) AS SET NOCOUNT ON;
IF @PolicyCategoryFilter = ” SET @PolicyCategoryFilter = NULL
DECLARE @sqlcmd VARCHAR(8000), @Text NVARCHAR(255), @Remain int SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting data integration for ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ‘ALL categories’ ELSE ‘Category ‘ + @PolicyCategoryFilter END RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the evaluation results. SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) ,cteEval AS (SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , Res.Expr.value(”(../DMF:TargetQueryExpression)[1]”, ”nvarchar(150)”) AS EvaluatedObject , (CASE WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”) = ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) = ”” THEN ”FAIL” WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) <> ”” THEN ”ERROR” ELSE ”PASS” END) AS PolicyResult , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage , CAST(Expr.value(”(../DMF:ResultDetail)[1]”, ”nvarchar(max)”)AS XML) AS ResultDetail , p.policy_id , c.name AS CategoryName , datename(month, EvaluationDateTime) + ” ” + datename(year, EvaluationDateTime) AS MonthYear , ”PowerShell EPM Framework” AS PolicyHistorySource , DENSE_RANK() OVER (PARTITION BY Res.Expr.value(”(../DMF:TargetQueryExpression)[1]”, ”nvarchar(150)”) ORDER BY Expr) AS [TopRank] FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //TargetQueryExpression” ) AS Res(Expr) WHERE NOT EXISTS (SELECT DISTINCT PHD.PolicyHistoryID FROM policy.PolicyHistoryDetail PHD WITH(NOLOCK) WHERE PHD.PolicyHistoryID = PH.PolicyHistoryID AND PHD.ResultDetail IS NOT NULL) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND EvaluationResults.exist(”declare namespace DMF=”http://schemas.microsoft.com/sqlserver/DMF/2007/08″; //DMF:EvaluationDetail”) = 1) INSERT INTO policy.PolicyHistoryDetail ( PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource ) SELECT PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource FROM cteEval WHERE cteEval.[TopRank] = 1′; — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting no target data integration’ RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the policies that evaluated with no target SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) INSERT INTO policy.PolicyHistoryDetail ( PolicyHistoryID , EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluatedObject , PolicyResult , ExceptionMessage , ResultDetail , policy_id , CategoryName , MonthYear , PolicyHistorySource ) SELECT PH.PolicyHistoryID , PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , ”No Targets Found” AS EvaluatedObject , (CASE WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) = ”” THEN ”FAIL” WHEN Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”)= ”FALSE” AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”)<> ”” THEN ”ERROR” ELSE ”PASS” END) AS PolicyResult , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage , NULL AS ResultDetail , p.policy_id , c.name AS CategoryName , datename(month, EvaluationDateTime) + ” ” + datename(year, EvaluationDateTime) AS MonthYear , ”PowerShell EPM Framework” FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //DMF:ServerInstance” ) AS Res(Expr) WHERE NOT EXISTS (SELECT DISTINCT PHD.PolicyHistoryID FROM policy.PolicyHistoryDetail PHD WITH(NOLOCK) WHERE PHD.PolicyHistoryID = PH.PolicyHistoryID AND PHD.ResultDetail IS NULL) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND EvaluationResults.exist(”declare namespace DMF=”http://schemas.microsoft.com/sqlserver/DMF/2007/08″; //DMF:EvaluationDetail”) = 0 ORDER BY DENSE_RANK() OVER (ORDER BY Expr);’ — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Starting errors data integration’ RAISERROR (@Text, 10, 1) WITH NOWAIT;
–Insert the error records SELECT @sqlcmd = ‘;WITH XMLNAMESPACES (”http://schemas.microsoft.com/sqlserver/DMF/2007/08” AS DMF) INSERT INTO policy.EvaluationErrorHistory( EvaluatedServer , EvaluationDateTime , EvaluatedPolicy , EvaluationResults ) SELECT PH.EvaluatedServer , PH.EvaluationDateTime , PH.EvaluatedPolicy , Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) AS ExceptionMessage FROM policy.PolicyHistory AS PH INNER JOIN msdb.dbo.syspolicy_policies AS p ON p.name = PH.EvaluatedPolicy INNER JOIN msdb.dbo.syspolicy_policy_categories AS c ON p.policy_category_id = c.policy_category_id CROSS APPLY EvaluationResults.nodes(”declare default element namespace “http://schemas.microsoft.com/sqlserver/DMF/2007/08”; //DMF:ServerInstance” ) AS Res(Expr) WHERE PH.PolicyHistoryID NOT IN (SELECT DISTINCT PH.PolicyHistoryID FROM policy.EvaluationErrorHistory AS PHD WITH(NOLOCK) INNER JOIN policy.PolicyHistory AS PH WITH(NOLOCK) ON PH.EvaluatedServer = PHD.EvaluatedServer AND PH.EvaluationDateTime = PHD.EvaluationDateTime AND PH.EvaluatedPolicy = PHD.EvaluatedPolicy) ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ” ELSE ‘AND c.name = ”’ + @PolicyCategoryFilter + ”” END + ‘ AND Expr.value(”(../DMF:Exception)[1]”, ”nvarchar(max)”) <> ”” –AND Res.Expr.value(”(../DMF:Result)[1]”, ”nvarchar(150)”) = ”FALSE” ORDER BY DENSE_RANK() OVER (ORDER BY Expr);’ — Remove duplicates
SELECT @Text = CONVERT(varchar, GETDATE(), 9) + ‘ – Finished data integration for ‘ + CASE WHEN @PolicyCategoryFilter IS NULL THEN ‘ALL categories’ ELSE ‘Category ‘ + @PolicyCategoryFilter END RAISERROR (@Text, 10, 1) WITH NOWAIT; GO
USE $(ManagementDatabase) GO EXEC policy.epm_LoadPolicyHistoryDetail NULL GO
USE $(ManagementDatabase) GO IF (SELECT SERVERPROPERTY(‘EditionID’)) IN (1804890536, 1872460670, 610778273, -2117995310) — Supports Enterprise only features BEGIN ALTER INDEX [PK_EvaluationErrorHistory] ON [policy].[EvaluationErrorHistory] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) ALTER INDEX [PK_PolicyHistoryDetail] ON [policy].[PolicyHistoryDetail] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) ALTER INDEX [PK_PolicyHistory] ON [policy].[PolicyHistory] REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) END; GO
ExtractConditionResults-PROC
USE [dbDooT] GO
/ Object: StoredProcedure [dbo].[ExtractConditionResults] Script Date: 10/05/2021 16:11:30 / SET ANSI_NULLS ON GO
SET QUOTED_IDENTIFIER ON GO
— Created by Tore Olafsson 07/05/2021 for the SQL Server part fo the dbDooT project
create procedure [dbo].[ExtractConditionResults] as SET NOCOUNT ON;
declare @datecondition varchar(50)
set @datecondition = FORMAT (getdate(), ‘yyyy-MM-dd’)
— Eliminate any results which have already been uploaded if not exists (Select EvaluatedPolicy from [dbDooT].[policy].[PolicyConditionResults] where EvaluationDateTime = (Select max(EvaluationDateTime) from [dbDooT].[policy].[PolicyHistoryDetail]) and EvaluatedServer in (select EvaluatedServer from [dbDooT].[policy].[PolicyHistoryDetail]))
BEGIN
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime > =’2021-05-06′
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
–To pick up values within Grouped PBM Condition Facets insert into [dbDooT].[policy].[PolicyConditionResults] SELECT DISTINCT e.EvaluationDateTime, e.EvaluatedPolicy, e.EvaluatedServer, e.EvaluatedObject, X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) as Name, X.Y.value(‘(ResultValue)[1]’, ‘VARCHAR(256)’) as ResultValue, e.PolicyHistoryID, e.CategoryName FROM [dbDooT].[policy].[PolicyHistoryDetail] e OUTER APPLY e.ResultDetail.nodes(‘Operator/Group/Operator/Operator/Attribute’) as X(Y) where X.Y.value(‘(Name)[1]’, ‘VARCHAR(256)’) is not null and e.EvaluationDateTime >= @datecondition
This is far from a complete guide but just meant as some tricks and tips regarding Always-On, please free to amend anything that is false and add other useful information to it.
If the Always-On dashboard is showing the databases as not synchronized (sync config) or not synchronizing (async config) then there are various steps that can be done so try and fix it:
First try to resume the data movement/connection for the database on both sides, some times this needs to be done on the DR side rather than the prod side to try both.
You can also try to suspend/resume the Data Movement, sometimes that helps.
Next check the permissions (access to dump directories) and do a connectivity check between the hosts.
The final option, if nothing else has worked, is to Remove and then Re-Add the database into the availability group (see below for instructions)
Further Syncing Troubleshooting Steps:
There are multiple reasons for the database not syncing status ranging from intermittent network issue, huge transaction, # of transactions, not ample space left on Secondary etc. The most common issue is probably intermittent network issue and not ample space left on the secondary. For example, a weekly maintenance job run and crate a huge log file. Some times, at the secondary server, there is not much space left for database file to grow and the Always On database synchronization status changes to one of the below.
Most of the time, when you see an issue with Always On availability group Synchronization it will be one of the below statuses for the Availability Database:
Database is Restoring
Database is Recovering
Database is in Recovery pending
Database is in Suspect
Database is in Emergency
Database is in Offline
Here are some steps to take if you encounter a recover Pending status: or any of the top 4 (Emergency and Offline are a bit different):
Step 1: Restarted the Windows Cluster service on SSCHA2 node
Step 2: Restarted the SQL Server service on SSCHA2 Node
Step 3: Waited for couple of minutes and I see Always On is in Synchronized again
In any of the above situation one has to take a judgement based on what has caused the Always On Synchronization status to change and resolve it based on it. Most of the time, manually pausing and resuming Always On / HADR will work, in other case one has to review the logs and take the call.
Here is how to How to Troubleshoot Always On Synchronization Issues in general, the commands are run on the Replica side:
Code to SUSPEND Data Movement in Always ON ALTER DATABASE <DBNAME> SET HADR SUSPEND
Code to RESUME Data Movement in Always ON ALTER DATABASE <DBNAME> SET HADR RESUME
Using Extended events for monitoring of Always-on Health
Launch SQL Server management studio on SQL01 ? Connect to the database engine ? Expand Always On High availability ? Expand Availability Groups ? Expand SQLCluster ? Right-click on Availability Databases ? Select Add Database.
The Add Database… to Availability Group wizard starts. You can view the details and list of tasks performed by the wizard. Click Next.
You can choose the database you want to add to the existing availability group. The list of databases is shown in the grid view with its status. You can select one or multiple databases from the list. In this demo, we are adding the StackOverFlow2010 database in SQLCluster, so tick StackOverFlow2010 from the list. Click Next.
On the Connect to Existing Secondary Replicas screen, you can view the list of replicas used to create the availability group. The SQL02 is in the list of secondary replicas. To grant the appropriate permission to the existing endpoints, we must connect to the secondary replicas. To do that, click on Connect.
A Connect to Server dialog box opens. You can select the appropriate authentication method. We use Windows Authentication, so select Windows Authentication from the drop-down box.
We can select the data synchronization preference on the Select Initial Data Synchronization screen. You can select any of the following methods.
Automatic seeding: SQL Server automatically creates the database and starts the seeding in this method. To use this method, the directory structure (data file path and log file path) on all participating replicas must be the same.
Full database and Log backup: The wizard will start the data synchronization by generating a full backup and log backup of the database. The backups will be restored on the secondary replicas and join the availability group. We must create a network share to keep full and log backups in this method. Make sure that it is accessible from all secondary replicas and has required permissions.
Join Only: This method is used when you have restored the backup of the database on secondary replicas. The wizard will start the data synchronization by joining the databases in an availability group.
Skip initial data synchronization: If you want to manually generate the full and log backup of the database.
In the demo, we are using the Full database Log backup method; therefore, select Full database and Log backup. The network shares to keep full, and log backups are \\DC\AGBackups therefore, specify it in the file share path. Click Next.
The wizard will run an availability group validation test. It checks the following parameters:
Shared Network location
Free disk space on secondary replicas
Checks whether the selected database exists on the SQL02 replica
Compatibility of the data file locations on the SQL02 replica
The wizard will not continue until all validation tests are completed successfully. In our demo, the validation test was completed successfully.
You can verify the configuration and settings we have selected in the wizard on the summary screen. Click on the script to generate the script of the task performed by the availability group wizard. Click on Finish.
The wizard begins the process to add the Stackoverflow2010 database in the SQLCluster availability group.
The time taken by the wizard depends on the time taken by the backup and restore process of the database. You can view the list of tasks completed by the wizard on the Results screen.
Once the database is added successfully, you can see it under the Availability Database node.
You can view it in the availability group dashboard. To open the availability group dashboard, Expand SQLCluster ? Right-click on Availability Databases and select Show Dashboard.
As you can see in the above image, the Stackoverflow2010 database has been added.
In Object Explorer, connect to the server instance that hosts the primary replica of the database or databases to be removed, and expand the server tree.
Expand the Always On High Availability node and the Availability Groups node.
Select the availability group, and expand the Availability Databases node.
This step depends on whether you want to remove multiple databases groups or only one database, as follows:
To remove multiple databases, use the Object Explorer Details pane to view and select all the databases that you want to remove.
To remove a single database, select it in either the Object Explorer pane or the Object Explorer Details pane.
Right-click the selected database or databases, and select Remove Database from Availability Group in the command menu.
In the Remove Databases from Availability Group dialog box, to remove all the listed databases, click OK. If you do not want to remove all them, click Cancel.
Removing an availability database from its availability group ends data synchronization between the former primary database and the corresponding secondary databases. The former primary database remains online. Every corresponding secondary database is placed in the RESTORING state.
At this point there are alternative ways of dealing with a removed secondary database:
If you no longer need a given secondary database, you can drop it.
If you want to access a removed secondary database after it has been removed from the availability group, you can recover the database. However, if you recover a removed secondary database, two divergent, independent databases that have the same name are online. You must make sure that clients can access only one of them, typically the most recent primary database.
Patching
To upgrade a SQL Server failover cluster instance, use SQL Server setup to upgrade each node participating in the failover cluster instance, one at a time, starting with the passive nodes. As you upgrade each node, it is left out of the possible owners of the failover cluster instance. If there is an unexpected failover, the upgraded nodes do not participate in the failover until Windows Server failover cluster role ownership is moved to an upgraded node by setup.
In other words we should really try to upgrade both nodes of am Always-On Cluster at the same time.
— SQL To check Database file usage, handy if you can’t see properties.
SELECT DB_NAME() AS DbName, name AS FileName, type_desc, size/128.0 AS CurrentSizeMB, size/128.0 – CAST(FILEPROPERTY(name, ‘SpaceUsed’) AS INT)/128.0 AS FreeSpaceMB FROM sys.database_files WHERE type IN (0,1);
select (”USE ‘ + QUOTENAME(@DBName) + N’; IF EXISTS (Select 1 from sys.objects where name = ””” + Object_name(major_id) + ””” INTERSECT SELECT 1 from sys.database_principals where name = ””” + USER_NAME (dp.grantee_principal_id) + ””” ) REVOKE ” + permission_name + ” ON [” + SCHEMA_NAME(SO.schema_id) + ”].[” + OBJECT_NAME(dp.major_id) + ”] FROM [” + USER_NAME(dp.grantee_principal_id) + ”]”) Collate Database_default as SQLTEXT from sys.database_permissions dp INNER JOIN sys.database_principals dps ON dp.grantee_principal_id = dps.principal_id INNER JOIN sys.objects SO ON dp.major_id = SO.object_id WHERE dps.name NOT IN (”public”, ”guest”) and dps.type != ”R”
UNION ALL
— Role Memberships
select (”USE ‘ + QUOTENAME(@DBName) + N’; If exists ( select 1 from sys.database_role_members where user_name(role_principal_id) = ””” + user_name(DRM.role_principal_id) + ””” and user_name(member_principal_id) = ””” + user_name(DRM.member_principal_id) + ””” ) Alter role [” + USER_NAME(DRM.role_principal_id) + ”] DROP MEMBER [” + USER_NAME(DRM.member_principal_id) + ”]”) Collate Database_default as SQLTEXT from sys.database_role_members DRM INNER JOIN sys.database_principals DP ON DRM.member_principal_id = DP.principal_id where DRM.member_principal_id > 1
UNION ALL
— Database Users
select (”USE ‘ + QUOTENAME(@DBName) + N’; If exists (select 1 from sys.database_principals where name = ””” + name + ”””) drop user [” + name + ”]”) Collate Database_default as SQLTEXT from sys.database_principals where principal_id > 4 and type IN (”S”, ”U”, ”G”) and name not in ( select user_name(principal_id) from sys.schemas where schema_id in (select o.schema_id from sys.objects o, sys.schemas s where s.schema_id = o.schema_id and o.schema_id between 5 and 16383) and schema_id between 5 and 16383 and principal_id between 5 and 16383)
‘;
print ‘Executing in database: ‘ + @DBName; exec sp_executesql @sql_perms;
CREATE
— Script to extract Database Security Objects for current database before a refresh
select (”USE ‘ + QUOTENAME(@DBName) + N’; If not exists (select 1 from sys.database_principals where name = ””” + dp.name + ”””) Create user [” + dp.name + ”]”) Collate Database_default as SQLTEXT from sys.database_principals dp where dp.principal_id > 4 and dp.type IN (”S”, ”U”, ”G”)
UNION ALL
— Roles
select (”USE ‘ + QUOTENAME(@DBName) + N’; If not exists (select 1 from sys.database_principals where name = ””” + dp.name + ””” AND type = ””R””) Create role [” + dp.name + ”]”) Collate Database_default as SQLTEXT from sys.database_principals dp where dp.type IN (”R”, ”A”) and dp.name <> ”public” and dp.is_fixed_role <> 1
UNION ALL
— Role Memberships
select (”USE ‘ + QUOTENAME(@DBName) + N’; If not exists ( select 1 from sys.database_role_members where role_principal_id = [” + USER_NAME(DRM.role_principal_id) + ”] and member_principal_id = [” + USER_NAME(DRM.member_principal_id) + ”] ) Alter role [” + USER_NAME(DRM.role_principal_id) + ”] ADD MEMBER [” + USER_NAME(DRM.member_principal_id) + ”]”) Collate Database_default as SQLTEXT from sys.database_role_members DRM INNER JOIN sys.database_principals DP ON DRM.member_principal_id = DP.principal_id where DRM.member_principal_id > 1
UNION ALL
— Object Permissions
select (”USE ‘ + QUOTENAME(@DBName) + N’; ” + dp.state_desc + ” ” + dp.permission_name + ” ON [” + SCHEMA_NAME(o.schema_id) + ”].[” + OBJECT_NAME(dp.major_id) + ”] TO [” + USER_NAME(dp.grantee_principal_id) + ”]”) Collate Database_default as SQLTEXT from sys.database_permissions dp INNER JOIN sys.database_principals grantee ON dp.grantee_principal_id = grantee.principal_id INNER JOIN sys.objects o ON dp.major_id = o.object_id WHERE grantee.name NOT IN (”public”, ”guest”);
‘;
PRINT ‘Executing in database: ‘ + @DBName; EXEC sp_executesql @sql_perms;
If you get a situation where a mirror failover hangs and you see a process blocked by -2 then take these steps:
Run a KILL based on the UOW_GUID with the transaction’s unit of work ID from sys.dm_tran_active_transactions.
Example:
SELECT * FROM sys.dm_tran_active_transactions WHERE transaction_id IN ( SELECT request_owner_id FROM sys.dm_tran_locks WHERE request_session_id = -2 );